Raft
raft资料 https://raft.github.io/
2. Motivation
2.1 Achieving fault tolerance with replicated state machines
Consensus algorithms for practical systems typically have the following properties:
- They ensure safety (never returning an incorrect result) under all non-Byzantine conditions, including network delays, partitions, and packet loss, duplication, and reordering.
- They are fully functional (available) as long as any majority of the servers are operational and can communicate with each other and with clients.
- They do not depend on timing to ensure the consistency of the logs: faulty clocks and extreme message delays can, at worst, cause availability problems. (不影响一致性)
- In the common case, a command can complete as soon as a majority of the cluster has responded to a single round of remote procedure calls; a minority of slow servers need not impact overall system performance.
3. Basic Raft algorithm
3.2 Raft overview
raft设计思想是有一个leader来处理共识,有了leader要方便的多,所以整个算法大致分为leader选举和log复制两个部分。并且要求任何时刻,提供以下safety保证
- Election Safety At most one leader can be elected in a given term.
- Leader Append-Only A leader never overwrites or deletes entries in its log; it only appends new entries.
- Log Matching If two logs contain an entry with the same index and term, then the logs are identical in all entries up through the given index.
- Leader Completeness If a log entry is committed in a given term, then that entry will be present in the logs of the leaders for all higher-numbered terms.
- State Machine Safety If a server has applied a log entry at a given index to its state machine, no other server will ever apply a different log entry for the same index.
(如果把raft也当做single-decree的,核心要求和basic paxos差不多,一定不能有两台server commit两个不一样的command。由于raft是multi-decree的,自然要求已经commit的内容不能修改删除,且日志要从头到尾保持一致)
3.3 Raft basics
在任何时刻,每个server处于三种角色之一
- leader
- follower
- candidate
leader处理所有客户端请求,角色转移如下:
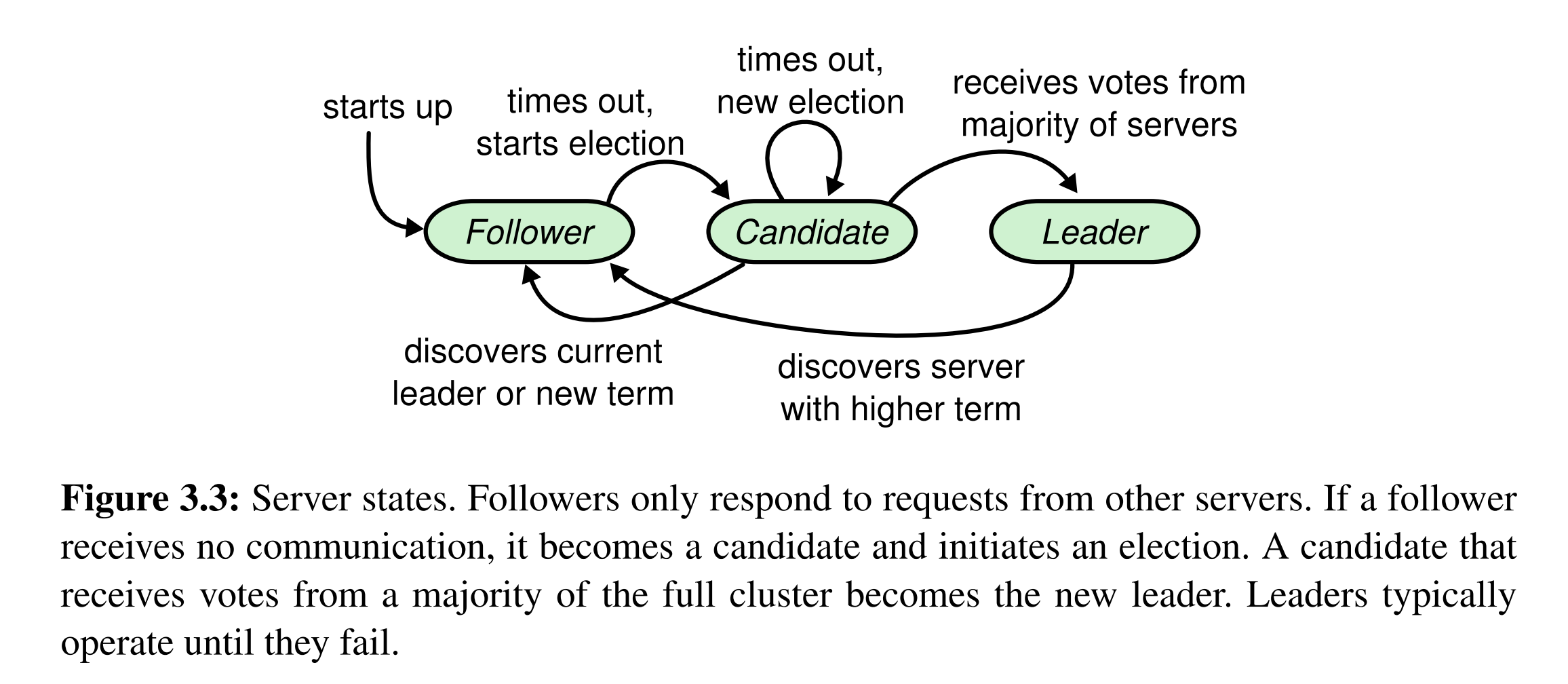
Raft把时间分成term,每个term的长度可以不相同。每个term都从选举开始,但不一定能选举成功,如果这一轮term结束选举失败,则新开一轮term。term作为逻辑时钟,每个server的term递增,且在互相交流时会带上term消息,term小的server会立即更新到大term。如果leader或candidate发现别人的term比自己大,就立即进入follower模式。如果server收到小term,则reject该消息(todo 是否会显式发送一个reject消息,还是忽略?)。
Raft通过RPC交流,基础算法只有两种RPC请求,RequestVote(candidate发起)和AppendEntries(leader发起)
3.4 Leader election
leader会定时发心跳消息给follower,如果follower长时间没有收到心跳包,则认为leader挂了,自己进入选举程序。
开始选举时,server先增加自己的term,给自己投票,然后发送RequestVote给其他所有server,每个server只可以投票一次。这个投票程序有3种结果
- candidate收到大多数投票,成为leader,然后发心跳告诉其他server自己是leader。
- 等待收集投票时,收到其他server发来的心跳包,如果这个心跳包的term不比自己的小,则进入follower角色,否则忽略不管。
- 既没有收到足够投票,也没有收到心跳包,在election timeout之后,进入下一轮选举。
为了避免一直处于状态3,raft选择随机每个server的election timeout时间在150~300 ms之间。
(上面这个算法是不严谨的,后续会添加约束。 按照上面算法,有可能一个term不是最大值的server当选为leader,但是当它和一个term更大的server交流时,就会又立马变成follower)
3.5 Log replication
leader接收客户端请求,先把请求append到自己的log中,然后发起AppendEntries RPC给每个server。当entry被大多数server复制后,leader将这条命令应用到自己的状态机上(commit),然后返回结果给客户端。此条内容commit时,This also commits all preceding entries in the leader’s log, including entries created by previous leaders.
每条log除了有用户的命令内容外,还包含当前的term,此外还有一个index用来标记log的位置。
Raft保证,每个commit的entry会持久化且最终一定被所有可用的状态机执行。
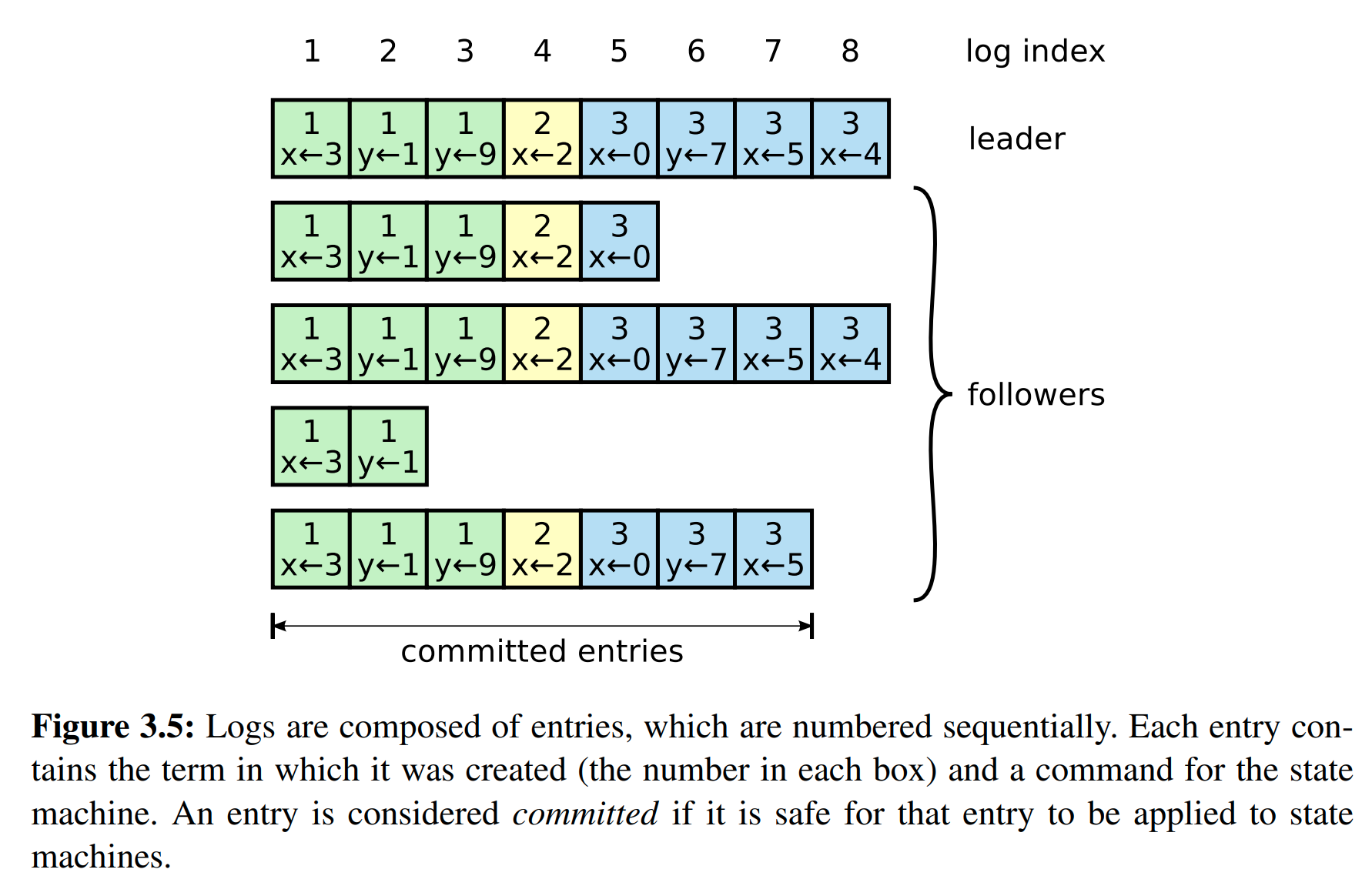
Raft通过以下保证来达成Log Matching Property
- If two entries in different logs have the same index and term, then they store the same command.(property)
- If two entries in different logs have the same index and term, then the logs are identical in all preceding entries.(property)
第一个保证因为一个leader在一个位置一个term只会发起一个entry,所以成立。第二个保证则从数学归纳法角度,只要从初始空状态一直保持就一直成立。
When sending an AppendEntries RPC, the leader includes the index and term of the entry in its log that immediately precedes the new entries. If the follower does not find an entry in its log with the same index and term, then it refuses the new entries.(implementation)
正常情况下,leader和follower的log内容是一样的,但是当有crash或者丢包时,会导致不一致。注意,这里的不一致包括未被commit的log内容,不是只考虑commit的。
Raft解决不一致的方法是,让leader强制改写follower的log。AppendEntries 请求会先检查一致性,只有当leader和follower的log保持一致才会执行成功。但是leader不会改写/删除自己的log。
3.6 Safety
3.6.1 Election restriction
定义: 两个server的log,比较最后一个entry,term大的log更up-to-date,如果term一样,log更长的那个更up-to-date.
为了保证新leader包含所有commit的log,要求follower投票的时候,只投给log不比自己晚的candidate。
3.6.2 Committing entries from previous terms
每个leader的term都不一样,即使一个leader宕机后重新掌权,且在期间其他server没有timeout,它也可能增加term.
leader收到request是追加在自己的log,但转发给follower的时候会指定position,而不是让follower也单纯追加log,所以相同position和term的entry,内容一定一样。log既是离散的(for follower)又是连续的(for leader)
log commit和apply是两个概念,commit了不代表已经apply,但是保证之后一定会apply。
为了让leader和follower数据一致,允许leader强制修改follower的内容。
对于旧term的entry,不通过计数的方式commit,而是等当前term有提案commit的时候,间接commit
大致了解可以到此为止,深入理解可以看 appendix 详细证明。