A Primer on Memory Consistency and Cache Coherence
原书: A Primer on Memory Consistency and Cache Coherence
1. Introduction to Consistency and Coherence
2. Coherence Basics
2.1 BASELINE SYSTEM MODEL
本文使用的模型是有write back cache的多核处理器。本文的baseline不考虑指令cache、多级cache、虚拟地址、TLB等常见功能。
2. 2 THE PROBLEM: HOW INCOHERENCE COULD POSSIBLY OCCUR
一个变量的值存在两个不同的cache中,当一个core修改了变量值,另一个cache的值没变时,就产生了INCOHERENCE。
2.3 THE CACHE COHERENCE INTERFACE
处理器和coherence protocol 通信接口可以概括为
- read request
- write request
就是读和写两种请求。
再根据协议本身和consistency model的关系,可以分为两类
- Consistency-agnostic coherence a write is made visible to all other cores before returning. cache 就像一个原子内存系统一样。对处理器来说,cache仿佛不存在。
- Consistency-directed coherence a write can thus return before it has been made visible to all processors。其他处理器的cache中可能会有stale value。协议需要保证写操作按某种约定的顺序对其他处理器可见。这种协议可以用在GPGPU上。
可能比较反直觉的是,我们日常PC系统实际是第一种协议。比如MESI协议,在写之前需要先将其他所有cache都invalid,因此这种操作可以看作是原子的。平时我们接触的多线程编程中,遇到乱序问题并不是coherence protocol导致的。本书介绍的也主要是第一种协议。
2.4 COHERENCE INVARIANTS
一种简单的invariant是,single-writer–multiple-reader (SWMR),即一次只能一个核写cache。此外,还需要保证各个核读到的值是一样的,且能读到最近写的值(Data-Value Invariant)。
coherence协议就是要保证上面两个invariant。
一般是以cache line作为管理单位。 Coherence不仅适用于L1 data cache,还适用于L1I-cache,L2 cache,TLB等所有用到共享地址空间的结构。Coherence对程序员不可见。
3. Memory Consistency Motivation and Sequential Consistency
3.1 PROBLEMS WITH SHARED MEMORY BEHAVIOR

r2的值可能为0,因为现代处理器可能乱序执行指令
- Store-store reordering 即使一切都in order,最后真正写cache的时候,C1可能因为S1 cache miss而先写S2
- Load-load reordering 类似的,可能因为cache miss,C2可能先读data,再读flag,特别是在没有分支依赖关系的时候。
- Load-store and store-load reordering 应该先load后store的时候,如果顺序颠倒了,就是Load-store reordering。假设store是一个unlock操作,那么把load调整到unlock之后就可能有问题。store-load则有可能是由write buffer的bypassing造成的。
3.2 WHAT IS A MEMORY CONSISTENCY MODEL?
a memory model, is a specification of the allowed behavior of multithreaded programs executing with shared memory. 多线程环境下,允许有多种不同的可能结果。
3.4 BASIC IDEA OF SEQUENTIAL CONSISTENCY (SC)
SC简单说就是各个core自己完全按program order执行,但由于不同线程交替执行,可能会产生一些不同的结果。
3.6 NAIVE SC IMPLEMENTATIONS
两种简易实现
- The Multitasking Uniprocessor 只有一个处理器,通过切换上下文执行不同的线程。
- The Switch 多核处理器,但是有一个全局的switch负责接收内存请求。处理器发出的请求必须是满足program order。
3.7 A BASIC SC IMPLEMENTATION WITH CACHE COHERENCE
假设cache维护了每个块的状态,比如 M 和 S (其实就是MESI的简化版),那么不同core对cache的访问可以是完全并行的(在没有读写冲突的情况下),而不需要像3.6节中那样,memory每次只选择一个核的请求。
3.8 OPTIMIZED SC IMPLEMENTATIONS WITH CACHE COHERENCE
现代真实的处理器有很多优化。
Non-Binding Prefetching
属于Software Prefetching,x86有专门的预取指令
Non-Binding Prefetching指把预取的内容放在cache中,binding prefetch指把预取的内容放在寄存器(有点像load)。
对SC的实现没有影响。
Speculative Cores
处理器会做分支预测,可能会提前load/store数据。如果预测失败,对于load没有什么影响,对于store,实际需要处理器commit指令的时候才会真正store。
Dynamically Scheduled Cores
乱序执行的core只会处理true dependency。可能会重排两个不同地址的load指令,这时候就会打破SC。
如果仍然要维护SC,需要在重排指令后额外追踪这些指令,确保在commit指令的时候,这些值和重排时load的值是一样的(但是可能有ABA问题)。
Multithreading
multithreading本身并不怎么影响SC,但是要注意,如果thread1有一个store指令,同一核上的thread2不能比其他核先看到这个store更新后的值。比如要保证thread2不能读到thread1的load/store queue。
3.9 ATOMIC OPERATIONS WITH SC
原子操作不会影响SC。原子操作可以不用锁住整个memory system,只需要保证这个变量只在当前core的cache中存在就好。
4. Total Store Order and the x86 Memory Model
4.1 MOTIVATION FOR TSO/X86
现代处理器一般都有store buffer,当store指令commit的时候,进入store buffer准备更新memory。通常会带有bypassing可以使load指令拿到最新的值。在单核系统中,store buffer可以是invisible的,但如果直接应用到多核系统,则会违反SC。
为了性能,最终舍弃SC
4.2 BASIC IDEA OF TSO/X86
SC要求以下4种操作的memory order要和program order一致。
- \[Load \to Load\]
- \[Load \to Store\]
- \[Store \to Store\]
- \(Store \to Load\) TSO舍弃了这个约束,只有SC有
在下面这种场景,TSO和SC是一样的
- core1 loads and stores to memory locations D1,…,Dn
- core1 stores to F (often a synchronization flag) to indicate that the above work is complete
- core2 loads from F to observe the above work is complete (sometimes spinning first and often using a RMW instruction)
- core2 loads and stores to some or all of the memory locations D1, . . ., Dn
TSO会允许SC不允许的情况出现,比如
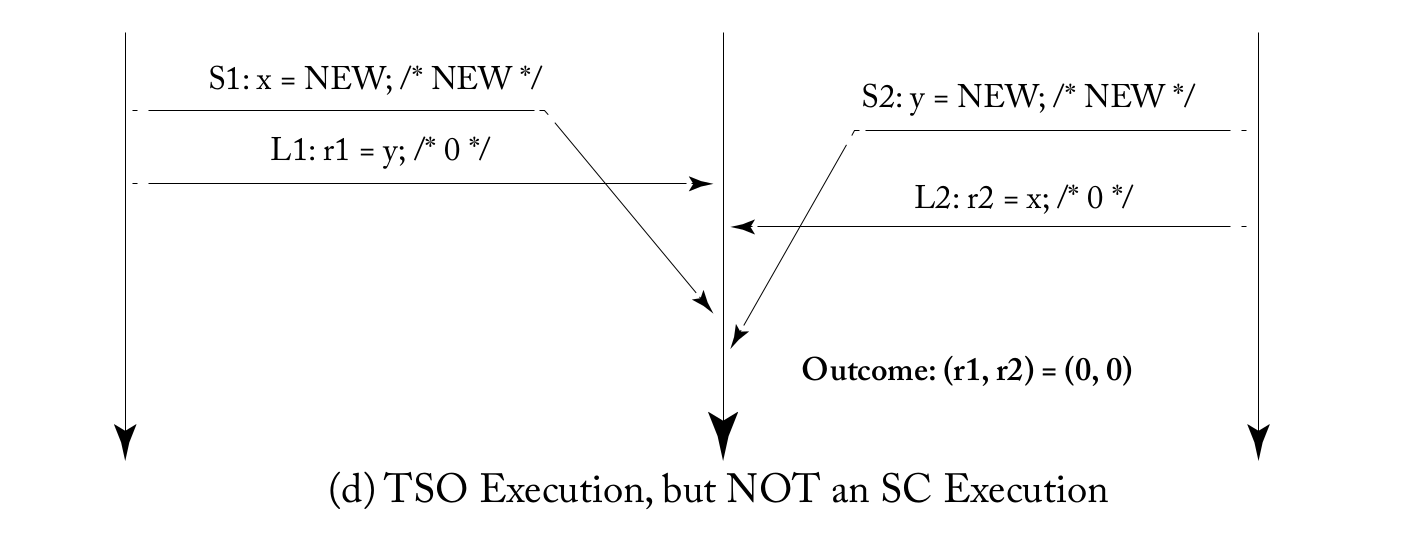
可以在S1和L1,S2和L2当中插入fence指令,保证S1比L1内存序在前,但TSO很少用fence,因为大多数情况用不到。
注意,TSO也不代表任意的store-load都可以重排

如果r2 = 0, r4 = 0,不能以为r1=0, r3=0. 在每个核执行的过程中,S1和L1有 true dependency,r1可以通过bypassing读到x的新值,r3同理。实际上r1一定是NEW,r3也一定是NEW。实际上,在Intel手册上也有说 Reads may be reordered with older writes to different locations but not with older writes to the same location. (这里的true dependency和体系结构中的true dependency不太一样,体系结构中主要是指寄存器之间的依赖,而这里是内存系统,但可以类比,如果write之后read同一个地址,被重排了,即使是单核处理器也是错误的,所以处理器一定会有额外机制保证不重排)
4.3 A LITTLE TSO/X86 FORMALISM
TSO要求如下
- 对于load-load,load-store,store-store,无论两个操作是同一地址还是不同地址,memory order都和program order一样。但是store-load不保证
-
load的值,要么来自按memory order最后一次store的值,要么来自按program order的值(也就是bypassing,这个时候其他核还不知道这个store)
- fence前后的memory order不可以乱,就是说fence前的load/store指令的memory order一定在fence后的指令的前面。
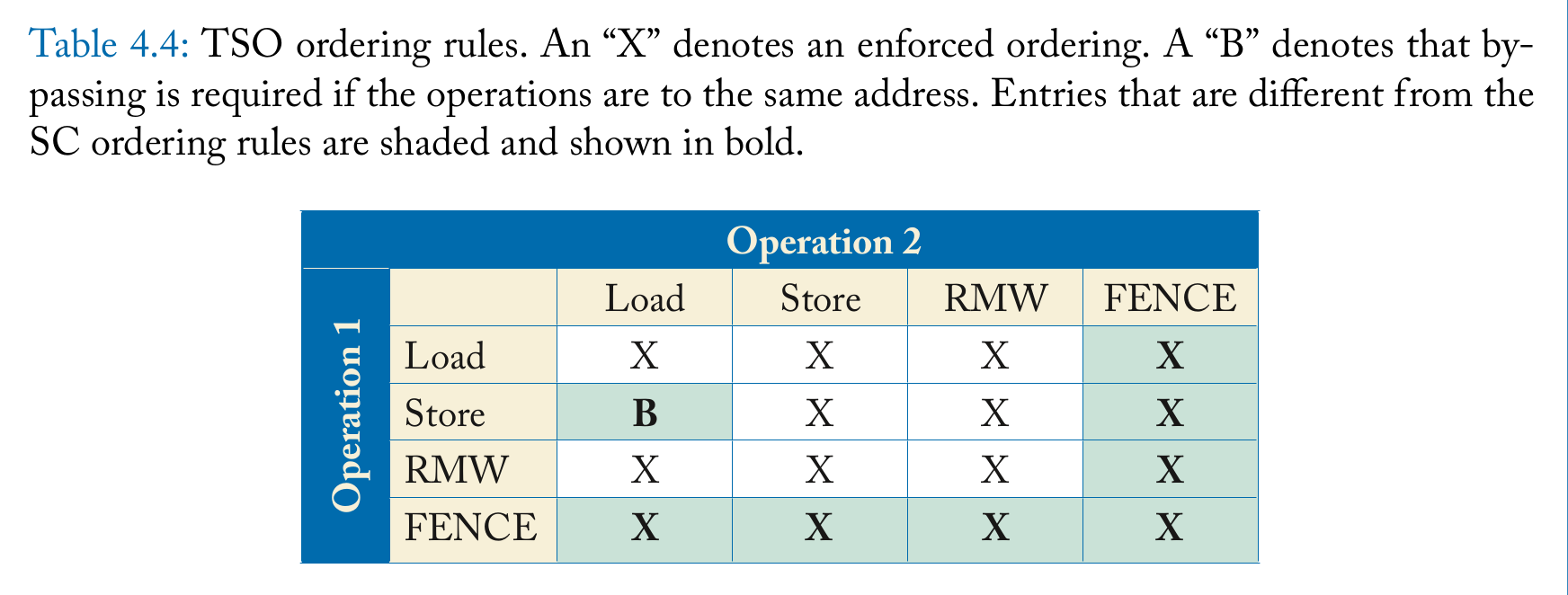
从表中可以看出,TSO除了store-load,其他都是memory order和program order保持一致。
普遍认为x86是TSO的,但x86官方没有给出形式化的说明,只有一些例子,这些例子目前是满足TSO的,如果以后出现反例,则不属于TSO
4.4 IMPLEMENTING TSO/X86
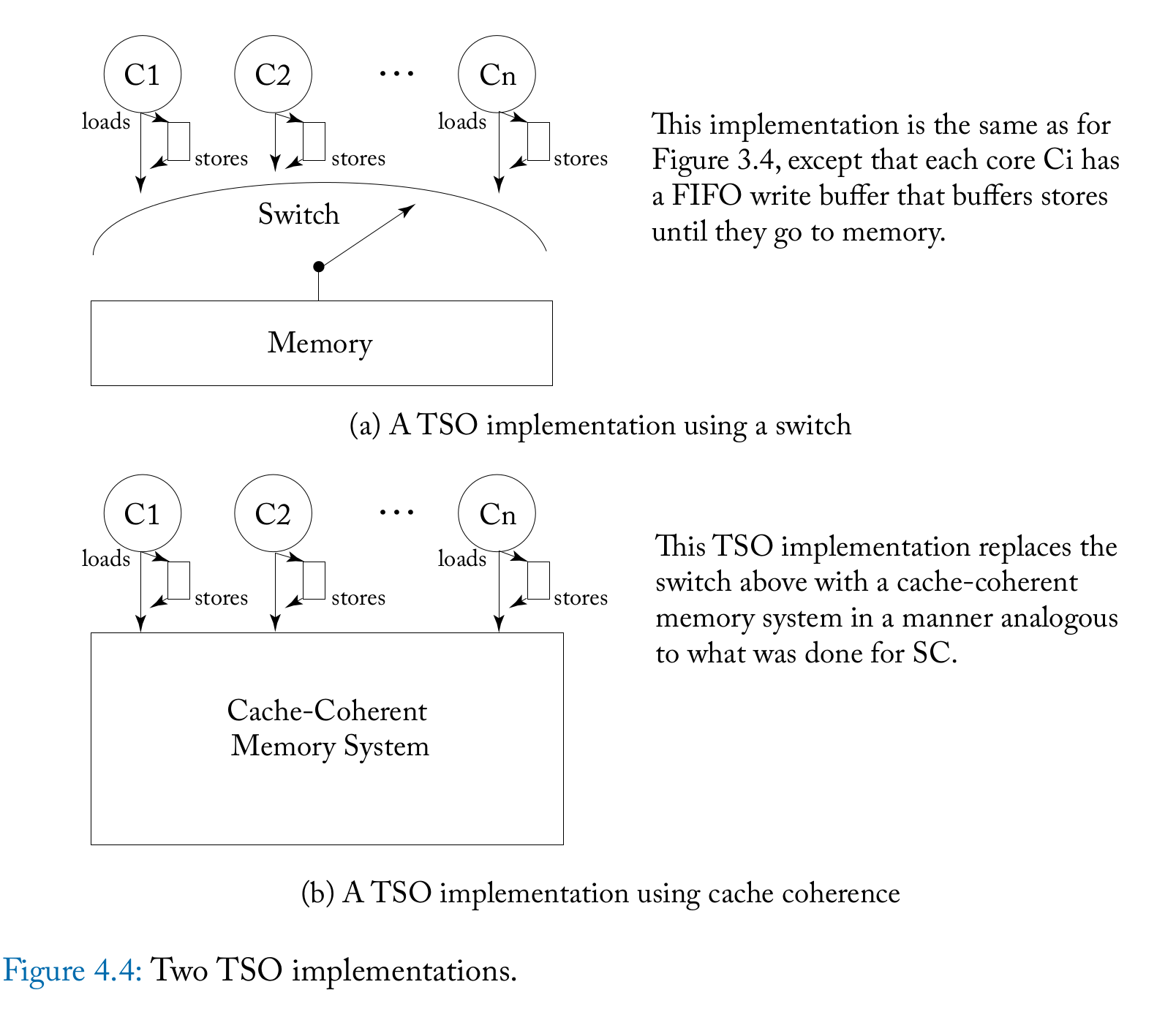
TSO主要是加了store buffer,将load和store分开。在现代superscalar processor中,基本也是这么设计的,load指令在计算出地址后直接访问内存,等load指令commit的时候更新ARF,如果load的时候cache miss则需要stall (如果访问内存的指令是in program order的,也可以通过某些机制不stall,如果是乱序的,显然还需要更多机制保证提前load的值是正确的)。但store指令要等commit之后再进入store buffer而不是算出地址立即访问内存,因为store指令如果最后不能commit,那么就不应该更新内存,因此store必须延后。
在本书TSO实现中,认为指令是in order离开core的,可以简单理解成是顺序执行处理器,这样load-load,load-store是显然的,因为load是立马访问内存,store-store因为write buffer是FIFO的,也成立。只有store-load因为有bypassing导致不成立。
4.4.1 IMPLEMENTING ATOMIC INSTRUCTIONS
对于TSO的原子操作,以RMW为例,先load后write,因为load和write需要原子化地执行,所以在执行时必须先将write buffer排空,否则不满足write-write,同时也不能和其他load重排,否则不满足load-load。
4.4.2 IMPLEMENTING FENCES
The semantics of the FENCE specify that all instructions before the FENCE in program order must be ordered before any instructions after the FENCE in program order.
For systems that support TSO, the FENCE thus prohibits a load from bypassing an earlier store.
fence可以实现的比较简单,清空write buffer,并且在commit前不执行load即可。
5. Relaxed Memory Consistency
6. Coherence Protocols
7. Snooping Coherence Protocols
8. Directory Coherence Protocols
附1 The x86-TSO Model
x86相当于下面这样一台抽象机,有write buffer,有bypassing,有全局的Lock,虚线内的是memory system,computation部分可以完全并行执行,且按in program order执行。
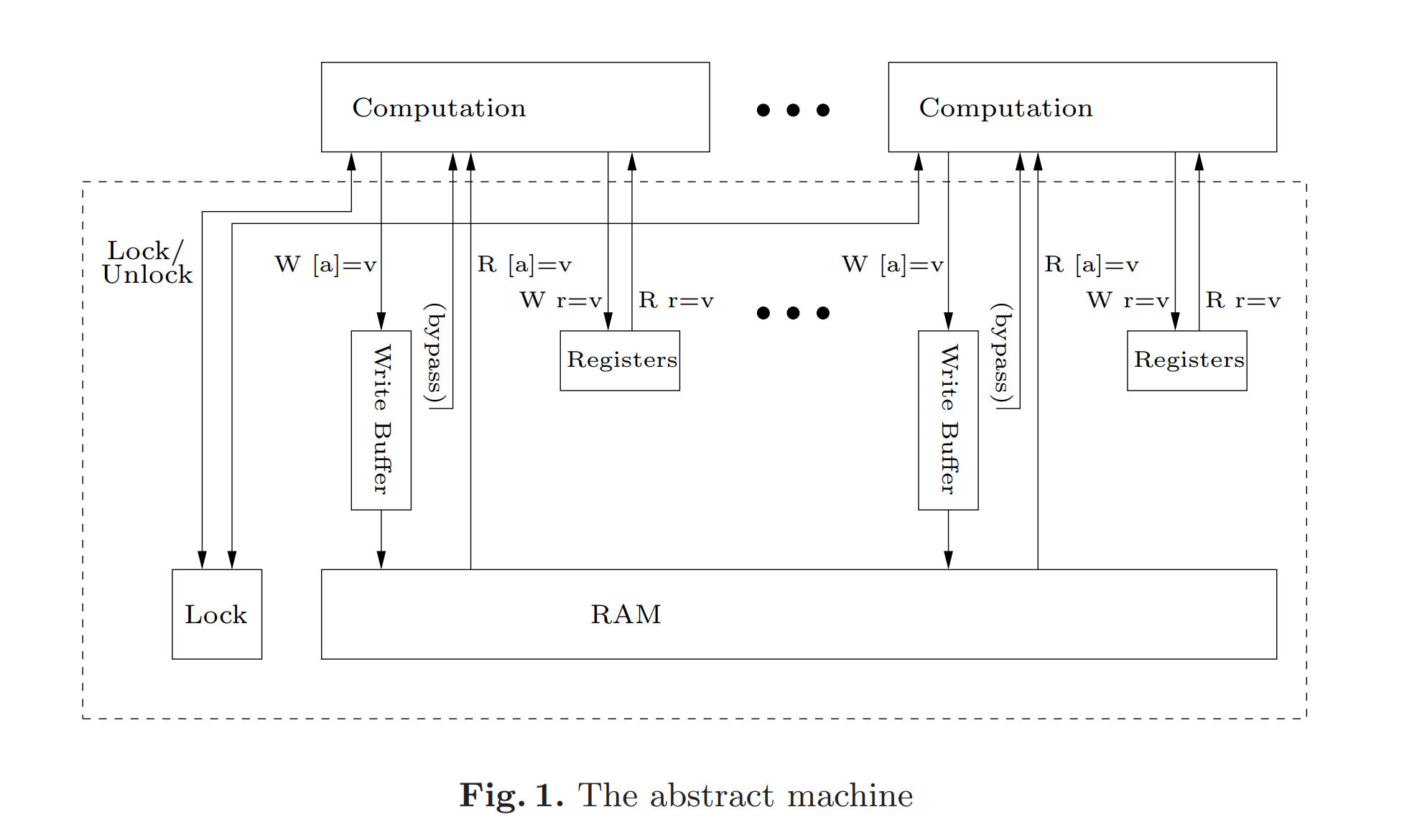
注意,这不是x86真实的结构,而是一台和x86相同功能的抽象机。
这台机器的状态由下面几个值组成
- R 每个核的每个寄存器状态
- M 每个memory地址的值
- B 每个核的write buffer的状态
- L 当前Lock的状态,要么有一个核持有Lock,要么都没有持有Lock
机器的状态会随着某个事件的发生而转移,事件有
- \(TAU\) 机器的内部动作
- \(EVT \ p \ a\) 核p发起一个action,这个动作是读/写 memory/register/write buffer/barrier
- \(Lock \ p\) 核p加锁
- \(Unlock \ p\) 核p解锁
为了描述状态转移,还需要引入两个定义
- not blocked 如果在状态s下,核p持有锁或所有核都不持有锁,那么核p是not blocked的
- no pending 核p的write buffer中没有地址a的项,即没有要写地址a的pending write,称为no pending
下面是可以转移的规则
-
Read from memory \(p\) can read \(v\) from memory at address \(a\) if \(p\) is not blocked, has no buffered writes to \(a\), and the memory does contain \(v\) at \(a\) (注意此时机器的状态是不变的,我们平时说的load指令实际包含两部分,一是从memory中读,二是将值写到寄存器,这里只是第一步,所以不改变机器状态)
-
Read from write buffer \(p\) can read \(v\) from its write buffer for address \(a\) if \(p\) is not blocked and has \(v\) as the newest write to \(a\) in its buffer (机器状态不变)
-
Read from register \(p\) can read the stored value \(v\) from its register \(r\) at any time; (状态不变)
-
Write to write buffer \(p\) can write \(v\) to its write buffer for address \(a\) at any time;(这时\(p\)的 write buffer变了,多了一项)
-
Write from write buffer to memory if \(p\) is not blocked, it can silently dequeue the oldest write from its write buffer to memory; (memory的值变了,write buffer也少了一项)
-
Write to register \(p\) can write value \(v\) to one of its registers \(r\) at any time; (寄存器状态变了)
-
Barrier if \(p’\)s write buffer is empty, it can execute an MFENCE (so an MFENCE cannot proceed until all writes have been dequeued, modelling buffer flushing); LFENCE and SFENCE can occur at any time, making them no-ops;(机器状态不变)
-
Lock if the lock is not held, and \(p’\)s write buffer is empty, it can begin a LOCK’d instruction;(改变了状态,注意还要求wb为空)
-
Unlock if \(p\) holds the lock, and its write buffer is empty, it can end a LOCK’d instruction. (改变了状态)
总体来说,和primer讲的TSO是差不多的,特别是barrier,TSO中也提出需要清空wb。 这里的Lock和Unlock其实就是原子指令,也是需要清空wb的,和TSO的描述一致。
补充:
MFENCE
和primer中的fence一样。
LFENCE
维护load-load, load-store关系,但这两条是x86本来就保证的,因此对consistency没有意义。但此外在实际实现中,lfence一定在其之前的所有指令完成后才执行,且其后的指令也只在lfence完成后才执行。这是对instruction ordering的保证。
SFENCE
sfence维护store-store关系,但是没有说load不可以和sfence重排,因为Intel手册原文是Reads cannot pass earlier LFENCE and MFENCE instructions. 所以sfence不能代替mfence,mfence是维护一切关系。
sfence还可能和non-temporal write有关,non-temporal write是指当要写一个值时,通常要先读一整个cache line,然后修改;如果现在要写的值不会在短时间内用到,那将其加载进cache是不划算的,non-temporal write就是直接从内存读后不经过cache,直接写回内存。
2个例子供练习,都涉及到先读后写同一个地址。

n5: 如果EAX是2,说明proc1在proc0之后修改x,于是EBX一定是2不可能是1。
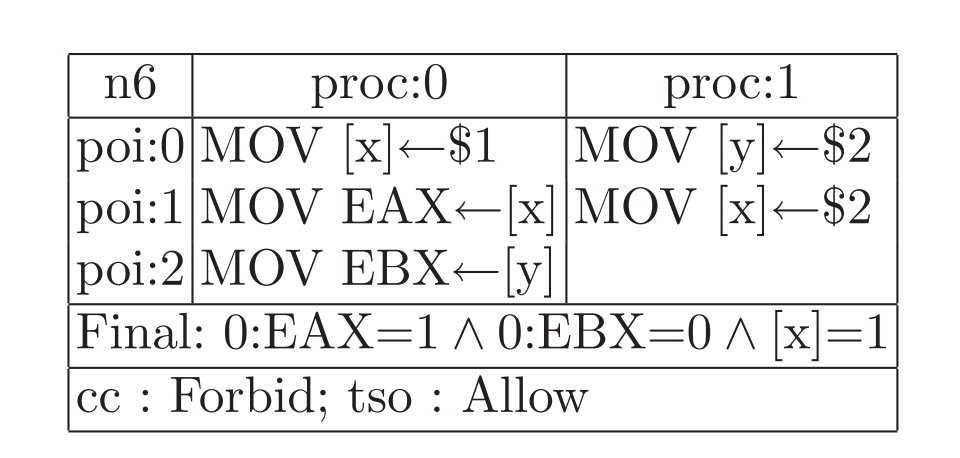
n5: 一种可能是,proc1先写y为2,放入proc1的write buffer,然后proc0执行,写 x为1并放入proc0的write buffer,然后EAX通过bypassing读到x=1,之后EBX读到0,之后proc1完成所有写入,最后proc0对x写1的操作才离开write buffer。
附2 C++ memory order
对于C++来说,对特定原子变量的修改顺序,所有线程看到的是一样的(All modifications to any particular atomic variable occur in a total order that is specific to this one atomic variable.)
对于同一个原子变量的所有原子操作(不同变量间没有下面的保证,比如可能重排relaxed操作),有以下保证
- Write-write coherence
- Read-read coherence
- Read-write coherence
- Write-read coherence
这四种关系,只要前一个操作 happen before 后一个操作,那么它们两个不会重排。
(这里容易和primer中的 load/store-load/store关系搞混,primer中的load-store关系是不区分变量的,load和store可以是两个不同的变量,且不要求原子变量,此外,load-store是指如果load 在 store 的program order前,那么也要在store的memory order前,实际只考虑了同一个thread下的顺序。 但是C++ memory order会考虑 inter-thread happen before 的关系,即线程间的同步操作。 这两个并不是描述同一件事情,primer描述了硬件保证了哪种程度的consistency,而C++ memory order描述了我们应该如何同步来保证程序结果的正确性)
1. Happen before
evaluation A happens-before evaluation B if any of the following is true:
- A is sequenced-before B.
- A inter-thread happens before B.
这里的happen before关系和上面又不一样,并不要求是对同一个变量的操作,只是两个evaluation
1.1 sequenced-before
描述的是同一个线程的关系,可以简单认为是program order。但是,如果同一个expression由多个subexpression组成,这些subexpression之间的顺序是未定义的,比如(a + b) + (c + d),有可能先算第一个括号里的,也有可能先算第二个括号里的。
1.2 Inter-thread happens-before
evaluation A inter-thread happens before evaluation B if any of the following is true:
-
A synchronizes-with B.
-
A is dependency-ordered before B.
-
A synchronizes-with some evaluation X, and X is sequenced-before B.
-
A is sequenced-before some evaluation X, and X inter-thread happens-before B.
-
A inter-thread happens-before some evaluation X, and X inter-thread happens-before B.
于是需要继续定义
1.2.1 Synchronizes with
If an atomic store in thread A is a release operation, an atomic load in thread B from the same variable is an acquire operation, and the load in thread B reads a value written by the store in thread A, then the store in thread A synchronizes-with the load in thread B. (注意要求是同一个变量)
1.2.2 Dependency-ordered before
Between threads, evaluation A is dependency-ordered before evaluation B if any of the following is true:
- A performs a release operation on some atomic M, and, in a different thread, B performs a consume operation on the same atomic M, and B reads a value written by A(c++ 20).
- A is dependency-ordered before X and X carries a dependency into B.
继续定义
1.2.2.1 Carries dependency
Within the same thread, evaluation A that is sequenced-before evaluation B may also carry a dependency into B (that is, B depends on A), if any of the following is true:
- The value of A is used as an operand of B (except 1. if B is a call to std::kill_dependency 2. if A is the left operand of the built-in
&&,||,?:, or,operators. - A writes to a scalar object M, B reads from M.
- A carries dependency into another evaluation X, and X carries dependency into B.
简单理解就是同一线程内有数据依赖。
2. Memory Order
2.1 Relaxed ordering
Relaxed不提供任何线程间的同步,只保证同一线程按program order运行(其实非原子变量也是)
// Thread 1:
r1 = y.load(std::memory_order_relaxed); // A
x.store(r1, std::memory_order_relaxed); // B
// Thread 2:
r2 = x.load(std::memory_order_relaxed); // C
y.store(42, std::memory_order_relaxed); // D
在上面代码中,允许最后r1 = r2 = 42,可以让B比A先执行,D比C先执行。
但是,Relaxed也不是可以完全任意重排的,如果有true dependency,肯定不能乱序(primer TSO中也有类似约束),比如下面
// Thread 1:
r1 = y.load(std::memory_order_relaxed); // A
if (r1 == 42) x.store(r1, std::memory_order_relaxed); // B
// Thread 2:
r2 = x.load(std::memory_order_relaxed); // C
if (r2 == 42) y.store(42, std::memory_order_relaxed); // D
这里r1=r2=42是不可能的,B必须在A执行完确定r1的值后才会执行,CD同理。
Relaxed主要用于计数。
2.2 Release-Acquire ordering
If an atomic store in thread A is tagged memory_order_release, an atomic load in thread B from the same variable is tagged memory_order_acquire, and the load in thread B reads a value written by the store in thread A, then the store in thread A synchronizes-with the load in thread B.
All memory writes (including non-atomic and relaxed atomic) that happened-before the atomic store from the point of view of thread A, become visible side-effects in thread B. That is, once the atomic load is completed, thread B is guaranteed to see everything thread A wrote to memory. This promise only holds if B actually returns the value that A stored, or a value from later in the release sequence.
同步只建立在release和acquire相同变量的两个线程间,其他线程可能看到不同的顺序。
在x86系统,release-acquire ordering对大部分操作来说是自动的,不需要额外机制实现(x86普通的load指令就可以实现release,因为当store离开write buffer的时候,其之前的store操作也一定离开wb了,反汇编也可以看出来)
Release-Acquire适合用于mutex的实现,一个线程释放锁(release),一个线程获取锁(acquire),那么释放锁前的内容都应该让另一个线程看到。
2.3 Release-Consume ordering
一个线程A的store操作带memory_order_release,另一个线程B的load操作带memory_order_consume,且B读到A的值,then the store in thread A is dependency-ordered before the load in thread B.
和release-acquire不同,不是A store前的所有写都对B可见,而是once the atomic load is completed, those operators and functions in thread B that use the value obtained from the load are guaranteed to see what thread A wrote to memory. 只有使用这个load值的操作才能看见,这就需要分析依赖关系,实际上consume很少使用,C++17开始甚至官方都不鼓励使用,Rust中甚至没有,所以了解下就行,不深究。
2.4 Sequentially-consistent ordering
标记memory_order_seq_cst 的原子操作,除了满足release/acquire那样store之前的操作对load都可见以外,还保证所有带此标记的操作满足single total modification order
原本以为SC因为限制最强会比较简单,但实际是最复杂的,特别是C++20对SC有了修改,弥补了之前定义在Power等其他机器上的错误,但是不影响x86,所以暂时不关注。SC操作不再只是维护同一个变量的同步关系,而是所有标记SC的操作。这些SC操作更像是一个个检查点,这些点是满足SC的,但是检查点之间仍然可以是乱序的。
对于x86来说,写操作的memory_order_seq_cst 实现方法是清空write buffer,这样这个操作线程后续的读操作必须等待,相当于维护了store-load关系。
x86是强一致性的
在C++ memory order章节中,有一段代码
#include <atomic>
#include <cassert>
#include <thread>
std::atomic<bool> x = {false};
std::atomic<bool> y = {false};
std::atomic<int> z = {0};
void write_x()
{
x.store(true, std::memory_order_seq_cst);
}
void write_y()
{
y.store(true, std::memory_order_seq_cst);
}
void read_x_then_y()
{
while (!x.load(std::memory_order_seq_cst))
;
if (y.load(std::memory_order_seq_cst))
++z;
}
void read_y_then_x()
{
while (!y.load(std::memory_order_seq_cst))
;
if (x.load(std::memory_order_seq_cst))
++z;
}
int main()
{
std::thread a(write_x);
std::thread b(write_y);
std::thread c(read_x_then_y);
std::thread d(read_y_then_x);
a.join(); b.join(); c.join(); d.join();
assert(z.load() != 0); // will never happen
}
上面这段代码要求必须使用memory_order_seq_cst,如果使用release或者acquire,z最终可能为0。
简化read_x_then_y()含义,其实就是判断对x, y的写操作是否为先写了x,再写了y,如果是,z就不会增加。同理,read_y_then_x() 是判断了是否先写了y,再写x。如果z为0,说明两个线程看到的对x,y的写入顺序是不同的,而这是release/acquire允许的,因为只保证了同一个变量的同步。
但是,在x86-TSO中,这是不会发生的,这个例子能体会到x86是强一致的。
