MODERN PROCESSOR DESIGN
书名: Modern Processor Design: Fundamentals of Superscalar Processors
1. Processor Design
主要讲述一些设计思想和计算性能指标。
2. Pipelined Processors
主要讲述基本的流水线处理器,且为load-store architecture,但这里的5级流水线和我们一般认为的5个阶段不太相同,划分为
-
Instruction fetch (IF)
- Instruction decode (ID)
- Operand(s) fetch (OF)
- Instruction execution (EX)
- Operand store (OS)
但是各个阶段可以有自己的submodule,怎么设计都OK,不过需要保证所用的硬件能满足设计要求。比如OF阶段可能要读两个寄存器操作数,而OS阶段需要写寄存器,那就要求register file至少有两个读端口和一个写端口。
2.2.3 Minimizing Pipeline Stalls
3种data hazard
- RAW (true data dependence)
- WAR (anti data dependence)
- WAW (output data dependenc)
实际上,在经典的标量5级流水线CPU中,只会出现RAW。
control hazard也可以看成是关于PC寄存器的RAW。一种优化是假设branch not taken,先执行,如果发现要跳转,将已经执行的指令取消。还有delayed branches,在跳转指令后插入与跳转无关的指令。但是这两种优化比较难结合起来,因为如果要跳转,在取消指令时要分辨出哪些指令是需要保留的。
一般地,我们能理解forwarding将 ALU或MEM 阶段的值转发给ALU input,但实际上也 可能 需要转发,取决于register file的硬件设计,如果在每个周期写执行写操作,后执行读操作,就不需要提前转发。另外注意,load forwarding paths 和 ALU forwarding paths 是两套硬件。
the resolving of pipeline hazards via hardware mechanisms is referred to as pipeline interlock(用来发现hazard,控制stall或forwarding).
2.2.4 Commercial Pipelined Processors

486处理器在decode阶段做地址翻译,在EXE阶段访问内存,但是x86系统还有microcode结构。
2.3 Deeply Pipelined Processors
流水线越深,理论上效率更高,但需要考虑更多的trade-off,比如hazard阻塞一次周期数更多(精简front-end模块),功耗问题,实际性能提升等等。
3. Memory and I/O Systems
3.3 Key Concepts: Latency and Bandwidth
Latency is defined as the elapsed time between issuing a request or command to a particular subsystem and receiving a response or reply. Latency一般比较难提高,往往受限于工艺技术或物理定律。
Bandwidth is defined as the throughput of a subsystem; that is, the rate at which it can satisfy requests. 在简单系统中,可能bandwidth就是latency的倒数。但现实中bandwidth可以比latency的倒数大很多,因为具备处理并发请求的能力,比如CPU到DRAM,所以多线程读写DRAM是可以提速的。
4. Superscalar Organization
简单的流水线很难每个阶段周期相同,比如浮点数运算很耗时。且当一条指令由于数据依赖要stall时,它后面的所有指令都要stall,即使后面的指令没有任何数据依赖,这样会影响性能。
Superscalar Pipelines优点
- Parallel Pipelines 一个stage可以有多条(宽度 width)指令执行,这当然也要求有多套硬件配置。比如Pentium处理器width为2,那么D-cache需要支持两个同时的内存访问(dual-ported),但这样硬件太贵,实际配置了single-ported D-cache,但是支持并发访问不同的bank。如果有bank冲突,则需要串行访问。
- Diversified Pipelines 每条pipeline可以有不同的function unit,它们的长度也可以不同。
- Dynamic Pipelines 支持乱序执行,但也不是彻底混乱,比如只是在EXE阶段乱序,但是in order commit,这样好处理异常。
总的来说,讲了一个in-order issue, out-of-order execution, in-order commit 处理器。
4.3 Superscalar Pipeline Overview
以一种简单的6-stage超标量流水线为例,这里的stage是logical的,不代表物理上这样划分。
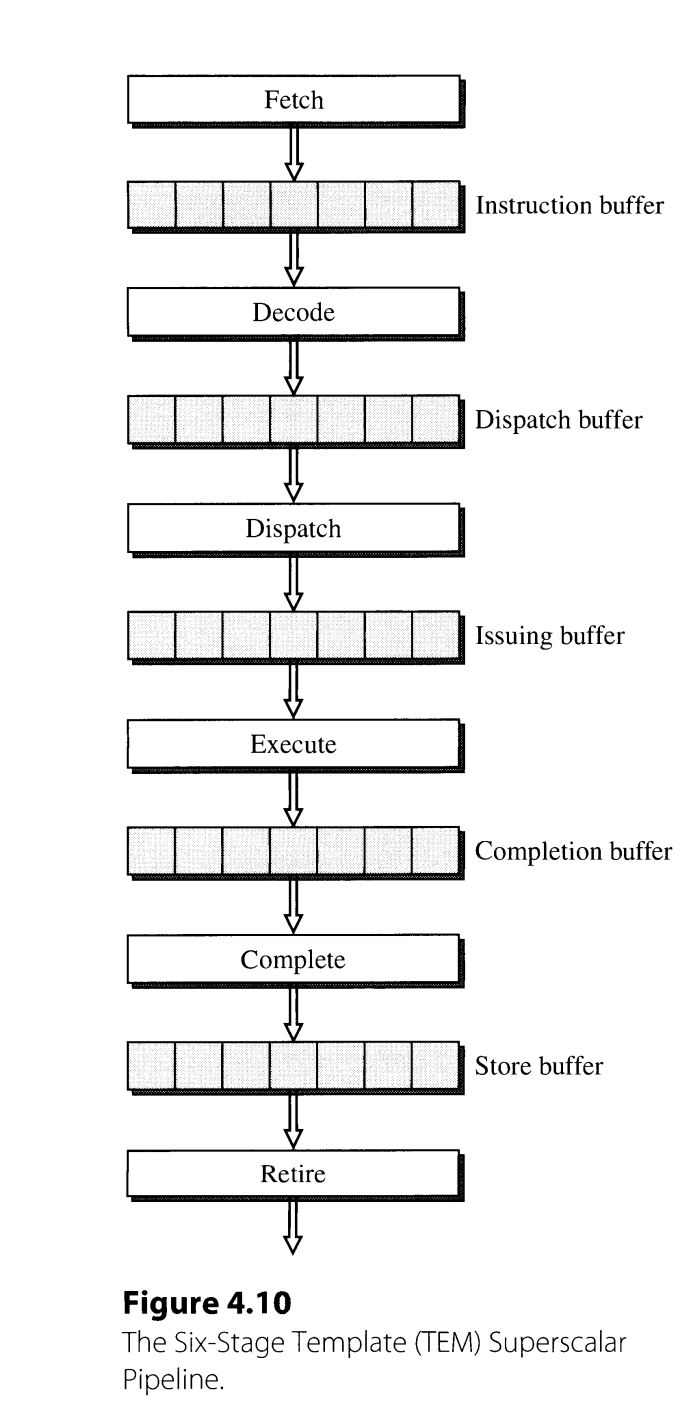
4.3.1 Instruction Fetching
一般来说,width为k的处理器,需要支持一个周期取k条指令。但是,如果k条指令超过了cache line边界,就会分两个周期读取,影响性能。如何处理分支指令会在第五章介绍。
4.3.2 Instruction Decoding
对简单的RISC来说,指令定长且种类有限,decode比较简单。但对于CISC来说,并行decode比较复杂,比如变长指令需要逐渐确定指令的长度。此外,CISC指令可能被翻译成更低级的指令,Intel称为micro-operations,比如奔腾处理器将IA32指令decode为采用load-store模型的微指令。这些微指令被多个decoder并行加载到 reorder buffer(ROB)中。所以CISC decode可能是非常复杂的。
一种decode优化是采用predecoding,在main memory和 I-cache间部分decode,存储对应信息在I-cache,这样从I-cache取指令时可以使用。predecoding会引起一次cache miss成本更高,但cache miss rate小的话问题不大;另外就是会增加I-cache size。
总之,decode是比较复杂的,可能会成为流水线瓶颈。
4.3.3 Instruction Dispatching
dispatching表示指令从decoding阶段出来后,被分配(dispatch)到某个function unit。issue表示指令真的进入function unit的时刻。
由于指令在decod阶段可能操作数还没有准备好,因此指令需要在reservation station(一种buffer)等待。reservation station可以有两种实现方式
- centralized reservation station 从decode阶段出来的各种指令都进入一个统一的reservation station,数据源准备好后再根据类型进入各自对应的function unit开始执行,这样dispatching和issue是一起的。这种实现对硬件利用率高,但实现复杂,Intel Pentium Pro采用这种。
- distributed reservation stations 每个function unit对应一个reservation stations,每条指令从decode出来根据类型被dispatching到对应的reservation stations,数据准备好后再被issue。
当然,实际设计中也可以二者混合,这里只是介绍两种思想。
4.3.4 Instruction Execution
还是如何设计的问题,有各种trade-off,比如function unit可以超过IF一次取指令的数量,但是太多又会使电路非常复杂。
4.3.5 Instruction Completion and Retiring
在指令完成execution后,不会立马结束,会被放进completion buffer(reorder buffer),这时还没有更新寄存器或内存,离开completion buffer后会更新寄存器或发起内存写请求。
在本书中,完成execution称为”finish”,退出completion buffer称为”complete”,如果要写D-cache,则在退出completion buffer后进入store buffer,退出store buffer真正更新完D-cache称为”retire”。但是这种叫法并不统一,不过一般都是要区分完成execution和更新完状态这两个不同的时刻。
5. Superscalar Techniques
5.1 Instruction Flow Techniques
主要关注branch指令。
目标是尽可能快地向流水线提供指令。主要介绍各种分支预测技术,本质还是基于历史预测或者由编译器给提示。
5.1.4 Branch Misprediction Recovery
如果预测错了需要恢复,方法是给每次预测的basic block分配一个唯一标识,标记为预测执行,当分支指令执行完发现预测错误后,终止执行标记的预测指令;如果发现预测正确,则取消预测执行的标记,当做正常指令。
5.1.6 Other Instruction Flow Techniques
如果处理器width比较大,可能一次取出多个branch指令,要为每个branch指令进行预测,然后从不同的target取指令,还需要注意对齐之类的,比较麻烦。Pentium 4引入了一种叫trace cache的结构,根据当前branch指令的地址和预测结果从trace cache取指令而不是从I-cache取指令。
5.2 Register Data Flow Techniques
主要关注ALU指令,不涉及memory。超标量处理器有WAR和WAW问题(统称false data dependences),需要识别并处理,只是stall的话很影响性能。
5.2.2 Register Renaming Techniques
注意,register renaming只是对destination register重命名,不是所有寄存器。此外,重命名更新映射关系是在decode阶段,这个时候指令仍然是in order的。因此以 WAR 为例,R指令会先读到某个寄存器r原来的映射位置,之后W指令才会更改这个寄存器r的映射位置,这样即使W指令先完成,乱序的R指令还是读到之前映射的位置,也就消除了 WAR。
5.2.3 True Data Dependences and the Data Flow Limit
无法突破true data dependence的限制,有时候必须等待。
5.2.4 The Classic Tomasulo Algorithm
该算法首次应用在IBM 360/9l浮点数单元上,首先介绍IBM 360浮点数单元的原本设计。IBM 360本身支持storage-register and storage-storage instructions,但是读写memory实际都不在FPU做(从FLB, floating-point buffer中读,写到SDB, store data buffer),因此FPU效率和register-register机器是一样的。FPU有2个function unit,都不是流水线化的,一个是加法器有2个周期的延迟,另一个做乘除法分别有3和12周期的延迟。浮点数指令由指令单元顺序进入floating-point operation stack(FLOS), 指令会进一步decode并按顺序从FLOS发射。
Tomasulo算法在原来FPU基础上增加了3个组件
- reservation stations
- common data bus
- register tags
在原来的设计中,因为function unit不是流水线的,因此当某个function unit正在执行时,FLOS中其他需要用这个function unit的指令需要等待。现在新加reservation stations可以视为虚拟的function unit,即使真正的unit正在工作,FLOS也可以按顺序issue指令到对应的reservation station中,或者operand还没等到,留在reservation station等待数据。 CDB其实就是做forwarding的工作,可以将function unit的值广播,这样指令可以更快拿到操作数。同时当读memory的数据在FLB准备好后,也可以通过CDB广播。
当FLOS将指令issue时,会检查操作数是否有效,如果有,就将其读到reservation station,否则设置一个tag,表示以后读这个tag对应的值。CDB的广播会带上这个值的tag,因此只需要做比较就好了。
这个tag的值实际上是最后一次写对应寄存器指令的id。举个例子,有以下指令,这里的write,read不是直接访问内存,而是说某个浮点数运算会读写到这些寄存器。下面这些指令按顺序decode。
1. write 1 -> x1
2. read x1
3. write 2 -> x1
4. read x2
指令1要写x1,就将FLR(floating-point register,可以理解为ARF中的寄存器) x1的”busy”位置为1,并且tag设置为指令1的id,这里就标记为1。指令2需要读x1,但是发现busy位被置为了1,说明要等待前面的指令完成,这时将tag值1写入到自己的reservation station栏中(而不是读这个时候x1的值),以后接收CDB广播比对tag就知道是自己需要的值了。指令3也要写入x1,假设这时候指令1还没有完成,其实并不影响,指令3会将FLR的tag置为3,这样后面的指令再读x1的值就知道要去找指令3的结果。指令4读x1,这时它要保存的tag值就是3了。
总得来说,Tomasulo可以简单理解为register renaming加上forwarding,解决了 WAW 和 WAR 问题。但是,却无法保证precise exception了,因为寄存器中间结果可能不提交,以上面的指令为例。假设指令1在指令3 dispatch之后完成,准备写x1,但这时FLR中的tag已经是3了,不会接收指令1的赋值,之后如果在指令3结束前发生异常,本来期待x1的值为1,但实际上可能不是。
5.2.5 Dynamic Execution Core
大多数现代超标量处理器都是in-order fetch/decode,out-of-order execution,in-order commit.
5.2.6 Reservation Stations and Reorder Buffer
The reorder buffer contains all the instructions that are in flight,包括在reservation station等待的指令,由一个ring buffer实现。
5.2.7 Dynamic Instruction Scheduler
有两大类调度器
- with data capture operand的值被复制到reservation station
- without data capture 只记录operand的tag,在真正执行前还要读寄存器。
5.2.8 Other Register Data Flow Techniques
在1960年代末1970年代初,人们认为遇到branch指令只能等待,但后面发展出了分支预测技术。
很长时间,人们又认为RAW依赖只能等待,但又有一些新的技术提出。
-
value prediction 直接预测某条指令的值,某些测试上有80%的准确率
-
dynamic instruction reuse 记录某些指令在某个输入下的输出值,当探测到同样指令同样输入重复时,直接用之前的结果,不重复计算
5.3 Memory Data Flow Techniques
5.3.1 Memory Accessing instructions
The execution of memory data flow instructions occurs in three steps: memory address generation, memory address translation, and data memory accessing.
假设是以寄存器间接寻址 + offset来产生地址,那么Load指令只需要operand ready时就可以issue进 function unit,Store指令则还可能等待要存储的值。
Store指令在计算出物理地址后不会像Load一样立即访问内存,而是和value一起进入reorder buffer,当指令complete的时候再写到内存。这样是为了避免乱序执行时,如果有 异常/分支预测失败 发生时,能撤销store指令。此外,写内存是先进入FIFO的store buffer(让读优先)。当store指令离开store buffer,真正向memory写入时,我们称指令这时候retire了(completion是更新CPU状态)。
5.3.2 Ordering of Memory Accesses
为了保证从异常中恢复,要求至少要按program order来更新memory。因此消除了WAW,WAR,但仍存在RAW问题。
5.3.3 Load Bypassing and Load Forwarding
Out-of-order execution of load instructions is the primary source for potential performance gain. 因为load指令将数据”写”到register,往往意味着后序指令要用,因此尽早load是可以提升性能的。
两种load优化
- load bypassing 当前要load x, 之前的store指令都不会写x,那么可以把load指令提前。
- load forwarding 当前要load x,之前的store指令会写x,那么可以直接把store要写的值转发给load。
假设load/store指令是in program order issue的,且load和store计算地址都需要2个周期(计算base+offset, translation),那么所有在load之前的store指令此时都已经计算好了地址,只需要和load地址比较即可,如果没有一样的,那么load不需要等待,可以访问内存;如果有一样的,那恰好可以用来做load forwarding,只是需要额外逻辑来选择匹配地址中最后一个store的。 但是前面这个方法要求内存指令in order issue,还是会影响性能。假如做乱序issue,则需要额外的机制来保证正确性,比如先假设没有依赖,将load读完后放入load buffer,每次store complete的时候检查load buffer中是否有依赖,如果有,就invalid 对应的load指令,并且重新执行load之后的指令,总之很复杂。
5.3.4 Other Memory Data Flow Techniques
除了processor这边的优化,也可以让cache有多个port,支持一个周期读多个位置,或者用cache bank,都是用来提高bandwidth。
此外还有
- nonblocking cache 如果遇到cache miss,将这个load放入missed load queue,然后继续服务其他请求,而不是一直阻塞到cache miss结束
- prefetching cache 需要 a memory reference prediction table and a prefetch queue 在当前load指令预测以后会load的地址
- load address prediction 和下面几个预测技术一样,都比较复杂,有需要再深入了解即可。
- load value prediction
- memory dependence prediction
7. Intel’s P6 Microarchitecture
P6在90年代问世,就是后面的奔腾处理器使用的架构,in-order fetch/decode/commit,只有执行部分是乱序的。英特尔指令被翻译成micro-operation执行。
记录的比较省略,因为不确定现代intel处理器是否类似设计,另一方面没有原文没有什么举例,看的也比较晦涩,毕竟现实CPU的设计非常复杂。
7.2 Pipelining
主要分3个阶段,依次介绍
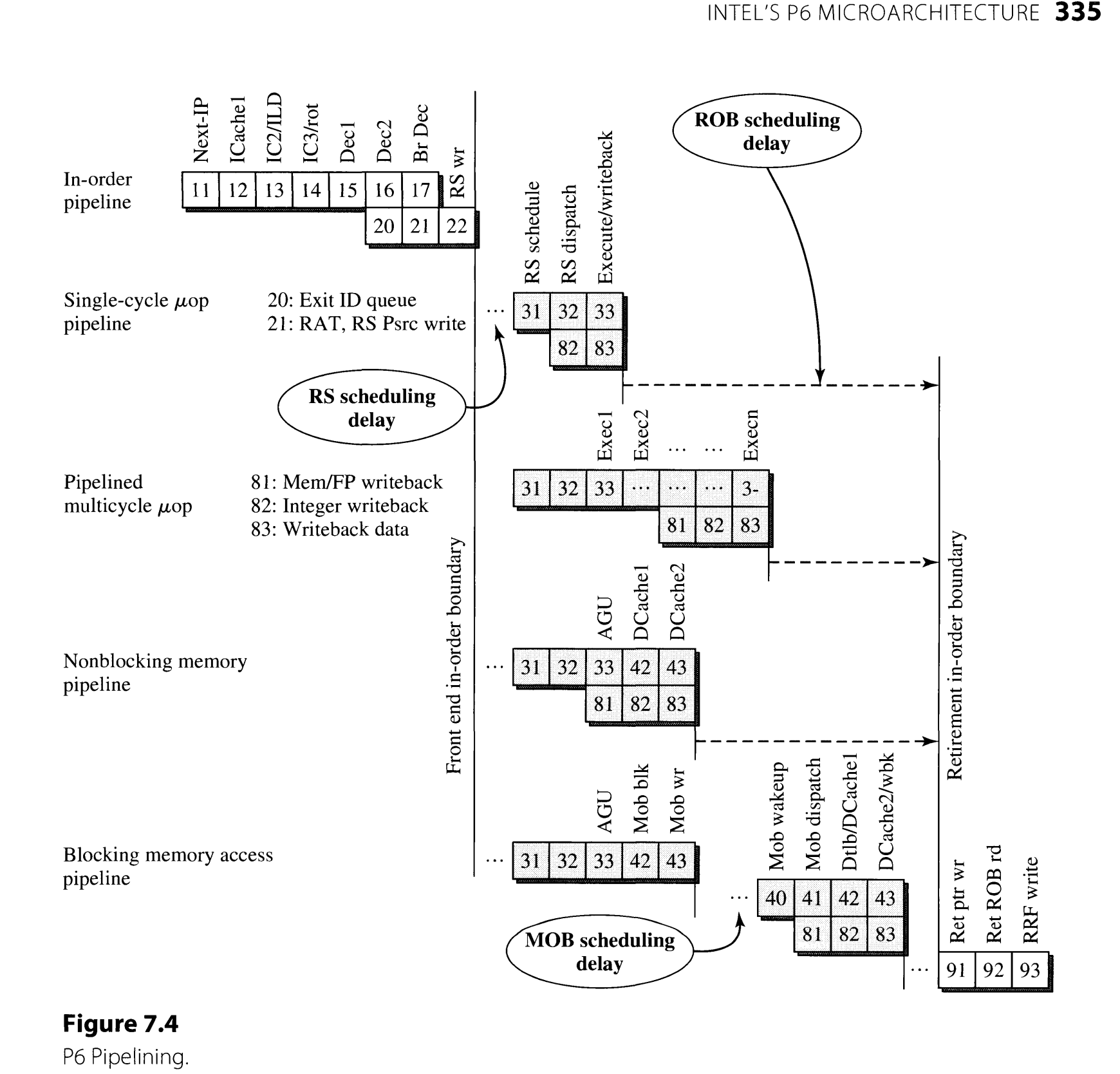
7.2.1 In-Order Front-End Pipeline
首先,第一个阶段(上图中的stage11)是branch target buffer (BTB)产生一个指令地址,然后stage12发起读指令,stage13继续访问I-cache,stage14完成取指令并将指令给decode阶段。
stage15,stage16做decode,将指令转成micro-operation。
stage17在某些情况下可以识别出跳转指令要跳转,这时可以清空in-order pipe,立即从target地址取指令。
stage21和stage17同时进行,做register renaming。stage22将指令放进reservation station等待,放进reorder buffer占位。
7.2.2 Out-of-Order Core Pipeline
RS决定哪些微指令可以开始执行,不仅仅关注操作数是否ready,FU是否可用,还会自己判断指令的优先级,因为只要没有依赖,就可以乱序执行。
在所有指令结束时,需要占用共享的writeback bus将结果写回寄存器(stage 83),因此RS在issue指令的时候就要考虑当指令结束时是否有writeback bus可用。
对于访问D-cache的指令,由AGU(address generation unit) 生成地址(stage33),然后访问cache(stage42 stage43),如果cache hit,则正常写入返回结果。如果cache miss,则该微指令被挂起,等待L2 cache返回,由MOB(memory ordering buffer)记录此次(load)访问。当cache内容ready时,由MOB重新唤醒此次访问的指令(stage40),然后再次访问D-cache。
7.2.3 Retirement Pipeline
Intel的ROB需要再把微指令组成完整的IA32指令,不能一次只commit部分IA32指令,界定指令范围会利用decode阶段给微指令打上的标记。因此在retire微指令时不能处理中断。
7.3 The In-Order Front End
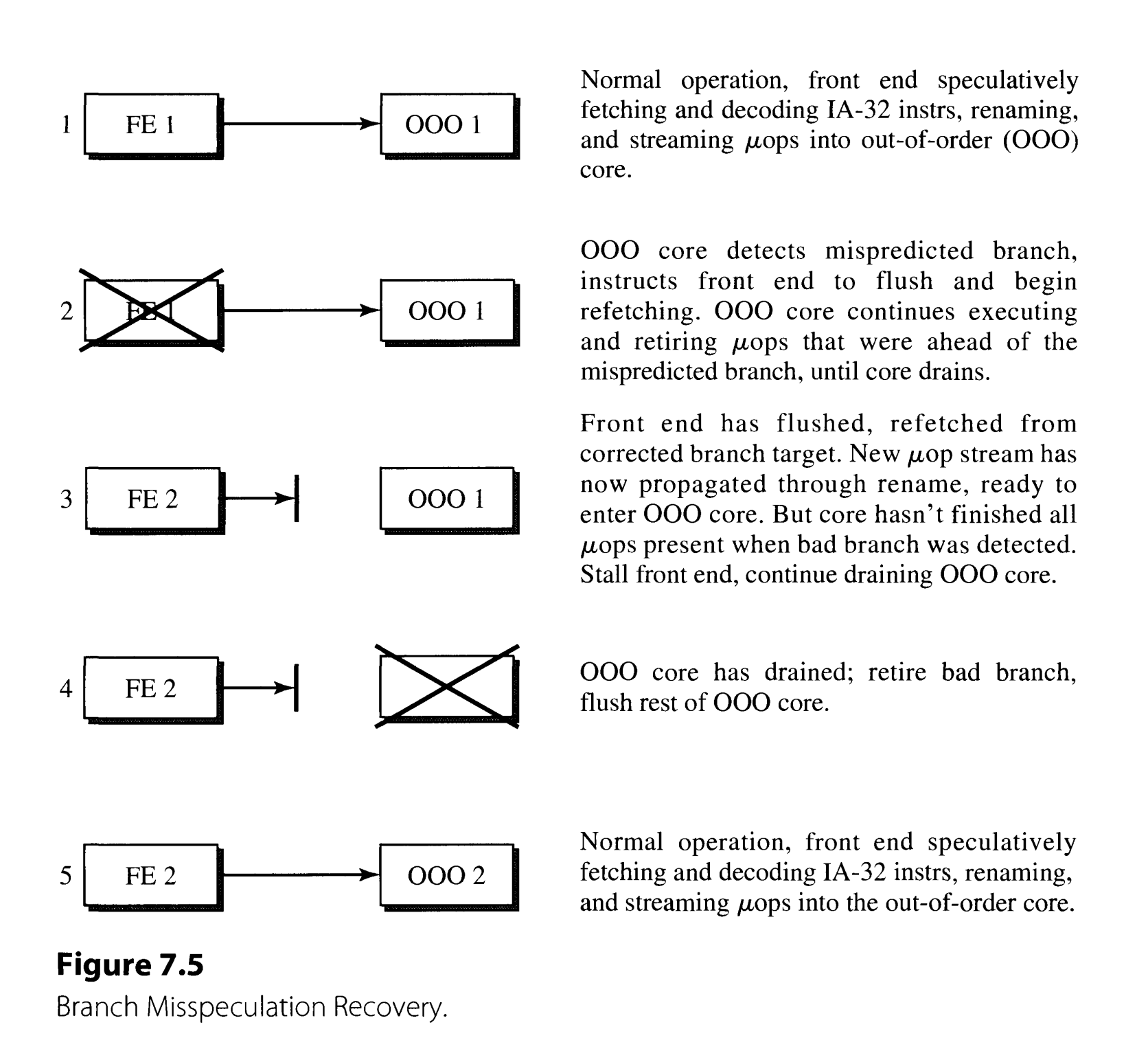
这个阶段的核心任务是尽可能取指令“喂饱”执行单元,当执行单元发现有分支预测错误时,会理解让FE从正确的地址取指令,但自己会继续执行指令,并且retire在跳转前的指令,并且执行单元会排空,如下图
7.3.1 Instruction Cache and ITLB
取指令不仅仅是从I-cache,也有instruction streaming buffer(prefetching得到的),两个任意hit即可。此外还会访问TLB查询物理地址(开page的时候),还会访问BTB(branch target buffer)
7.3.2 Branch Prediction
分支预测在stage12,验证分支预测的正确性可以在stage17或者JEU(jump execution unit, stage33)。BTB只有在JEU算出来的时候才会更新。
P6的分支预测使用two-level adaptive training algorithm。主要还是依赖分支历史,具体算法略过,感觉不是很重要。
7.3.3 Instruction Decoder
ID的第一个阶段是instruction steering block (ISB),负责将指令顺序取出并发给对应的3个decoder。取指令是一次读16个byte。除了decoder外,还有microcode sequencer(MS) microcode read-only memory (UROM),负责一些复杂指令的decode工作。
7.3.4 Register Alias Table
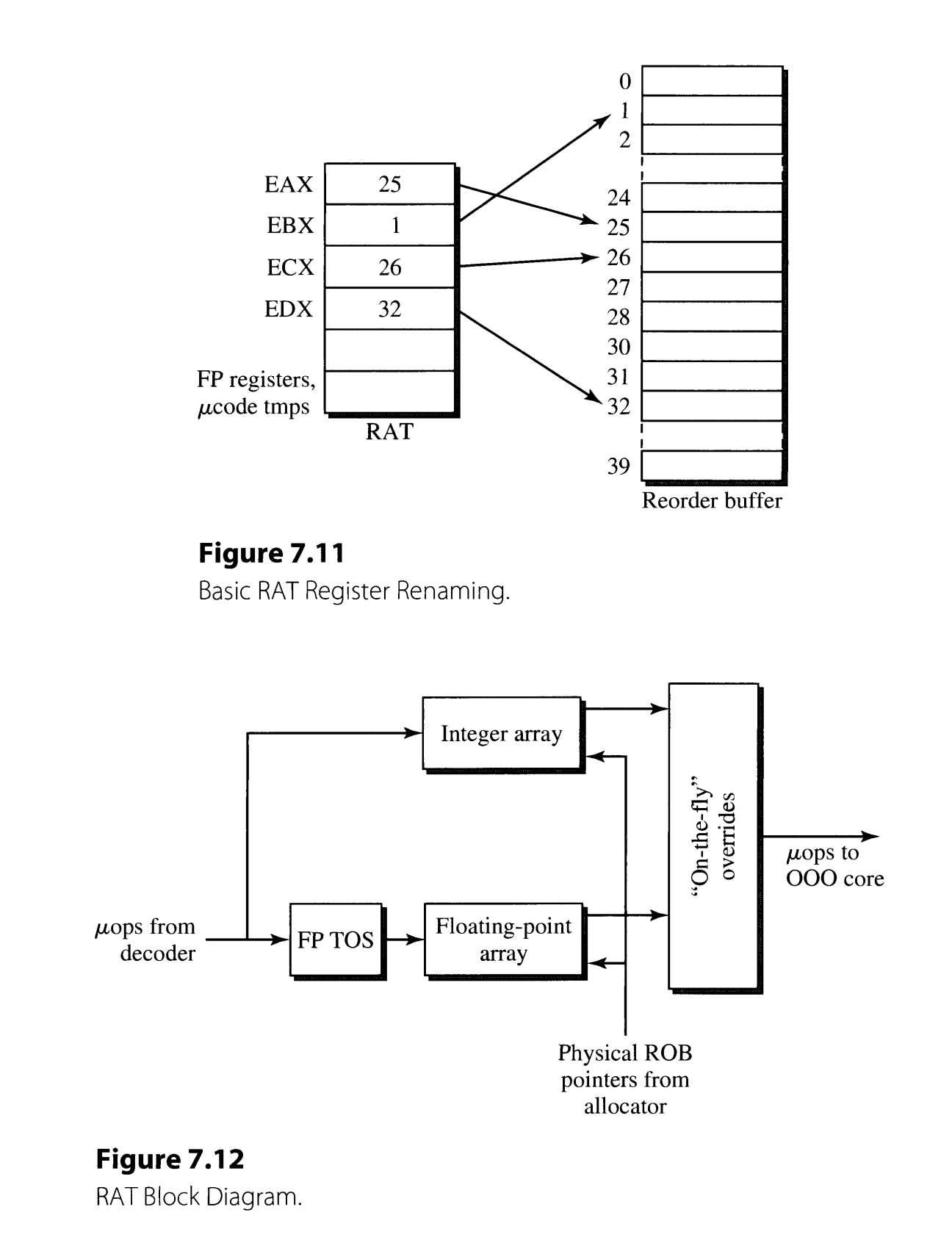
register alias table (RAT)将寄存器映射到ROB中。
7.4 The Out-of-Order Core
7.4.1 Reservation Station
RS 是微指令执行前存在的地方,负责检查指令所需操作数是否ready,执行单元是否ready,乱序调度指令且bypassing value等。
一共有5个schedulers,每个对应一个execution unit。
7.5 Retirement
ROB中存储了运算结果的值,这样既支持了分支预测执行,又支持了寄存器重命名
7.6 Memory Subsystem
memory ordering buffer (MOB)连接OOO engine和memory system。包含两个主要buffer,load buffer(LB) 和 store address buffer(SAB) 都是环形buffer,每个entry代表一个load/store指令。
SAB和memory interface unit’s (MIU),store data buffer (SDB),DCache’s physical address buffer (PAB)一起工作。
SAB,SDB,PAB可以看成一个统一的store buffer(SB)
LB包含16个load entry,里面存放的是RS dispatch时无法完成的load操作。LB会监听外部事件,其他core写某个位置时,会让OOO engine重新发起这个load请求。
SB包含store操作,这些操作是in program order的。
RS在issue load/store指令的时候,就会给它们在MOB分配对应的entry。
11. Executing Multiple Threads
11.2 Synchronizing Shared-Memory Threads
除了常见的原子指令用于同步。现代指令集MIPS、PowerPC、IA-64都提供一种Load-linked/store-conditional(ll/stc)的同步原语. 就是先load一个地址的值,然后进行任意计算,最后将结果写回。但是要求写回结果的时候,那个地址的值没有被更新过,否则写回失败。即使那个地址的值和load时读出来的一样,如果中间被修改过仍然不能成功写回,因此这种机制比简单的原子指令compare-and-swap更严格。这种机制的实现由硬件完成,流水线记录某个地址有没有被修改过。
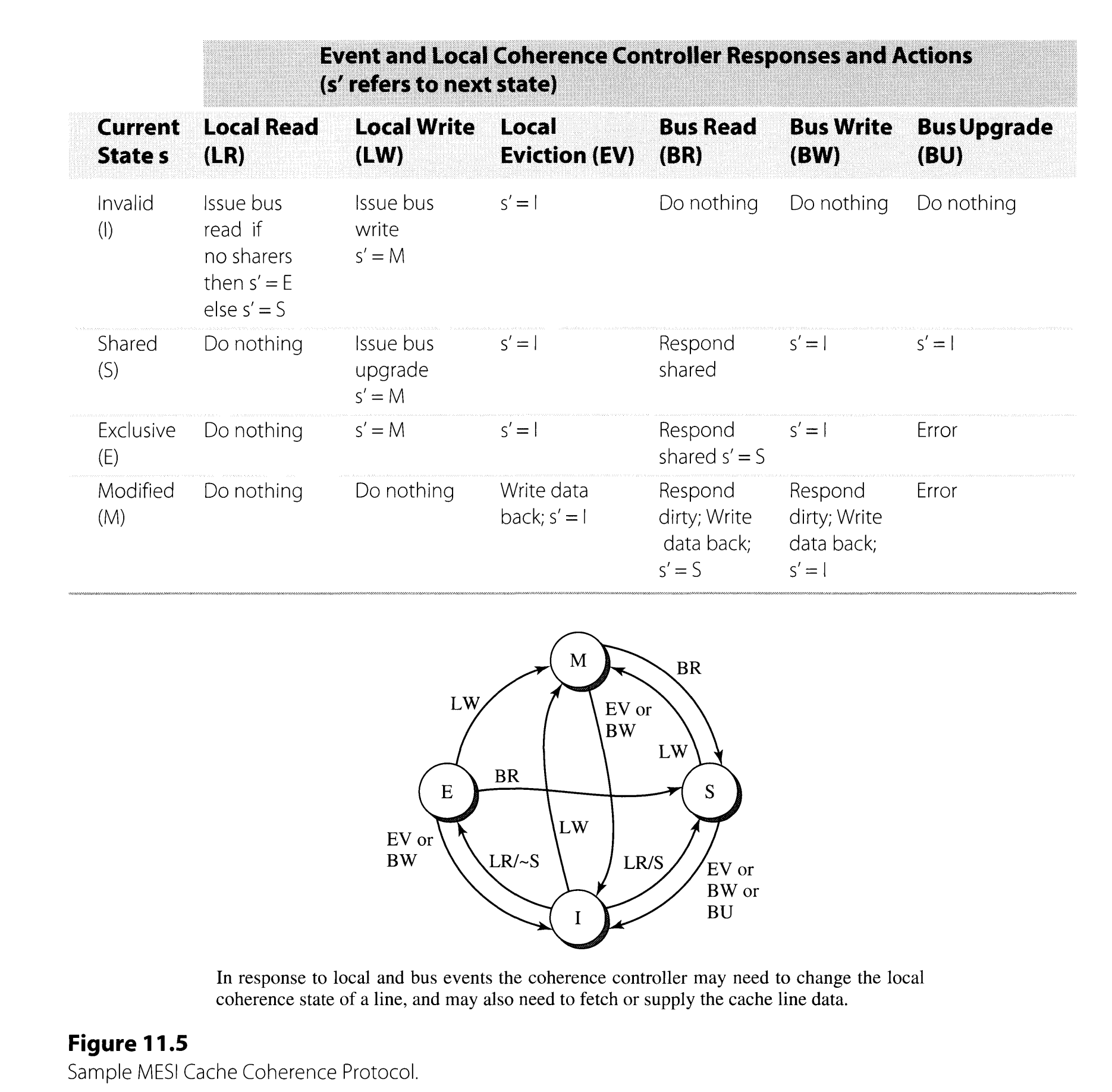
MESI协议,注意S状态和I状态,当要写时,一个是发起的bus upgrade,一个是发起bus write,不一样的。
AMD使用MOESI协议,增加了一个O状态(Owned), O状态可以由M状态转来,当M收到一个读请求,这时候可以不用将dirty cache line写回内存,直接把cache line给其他核,然后自己进入O状态,用来负责以后将cache line写回到memory。
Intel使用MESIF协议,多了一个F状态(Foward),只能有一个,最后一个读cache line的记为F,用来响应bus read。原来的MESI是所有S都响应bus read。
- snooping Implementations 可以简单理解成所有核都连在一根bus上,每个processor广播消息也接收消息。这种实现比较直接,但不适用于几十个核以上的情况,因为比较消耗bandwidth。
- Directory Implementation 将所有cache的状态信息单独保存在一个地方,每次通过查表来进行点对点通信。
11.3.5 Multilevel Caches, Inclusion, and Virtual Memory
- Noninclusive Caches 将不同level的cache当做独立的cache,因此比较复杂
- Inclusive Caches L1cache的值一定在L2cache中,这样实际只需要考虑L2的cache coherence,实现简单。
11.3.6 Memory Consistency
Sequential Consistency是好的,但是过于严格,实际上并不需要实现SC。就好像乱序执行一样,只要保证true dependency就好了,不需要严格按program order执行。
11.3.6.2 High-Performance Implementation of Sequential Consistency
大概是讲cache coherence协议其实是帮助建立了处理器之间的依赖关系,比如RAW,一个processor读另一个processor之前写的值,那么首先自己的cache回收到invalid请求,然后cache miss再去读新的值。 一种实现方法是仍然让load指令乱序发射,但是load queue记录下来,在这条load指令commit之前如果收到invalid请求,和load queue比对,有匹配的就和分支预测失败一样重新执行。
在MIPS R10000, Intel Pentium Pro上有类似实现,但是没有具体的文献引用,所以不太确定是否理解正确。
11.3.7 The Coherent Memory Interface
对于uniprocessor,访问内存的简单实现可以看成原子操作,获取bus,发出请求,然后一直hold the bus直到返回结果。更先进的实现是split transactions,发出请求后释放bus,下个周期可以再发出新的请求,之后再获取第一次的结果,不过这样的实现会比较复杂。
11.4 Explicitly Multithreaded Processors
- Fine-Grained Multithreading 除了register file和control state/logic,其余硬件共享。在固定周期数切换线程。
- Coarse-grained Multithreading 除了register file和control state/logic和I-fetch buffer,其余硬件共享。在线程执行stall时切换。
- SMT 差不多只有function unit, cache共享(decode, rename, issue也可以共享,看具体实现) The final and most sophisticated approach for on-chip multithreading is to allow fine-grained and dynamically varying interleaving of instructions from multiple threads across shared execution resources.
SMT的实现
- Fetch 给I-cache设置两个port是比较贵的,可以考虑time-sharing。同样,分支预测也更偏向于time-sharing,如果共享的话,线程交替执行可能反而导致效果不好。
- Decode decode需要分析依赖,对于RISC来说,更适合两个线程分成两组单独处理,简单有效,但可能会限制单个线程的效率。对于CISC来说,decode非常复杂,使用time-sharing可能更好
- rename 因为每个线程需要自己的rename table,可以两个线程分开,但和decode一样,可能会限制单个线程的效率。
- issue issue只关注线程内的依赖关系,因此可以分开。
- execute 自然是共享的
- memory 共享cache可以,但是load/store queue可能还是要分开
- retire 分开的
Pentium 4 Hybrid Multithreading Implementation
hyperthreading和SMT概念上比较相似。在Pentium in-order的部分采用的是fine-grained,比如fetch,decode和retire是交替执行的,但如果一个线程遇到stall,另一个线程可以使用全部硬件(从实现上来看,可以解释为什么超线程不能100%提升性能)。
11.5 Implicitly Multithreaded Processors
implicit multithreading (IMT) describe techniques for automatically spawning such threads by exploiting attributes in the program’s control flow. 不需要由程序员来创建thread。
未完待续,不是特别重要但比较有趣。