CMU15-445 2021 Fall bustub实验记录
每个人的实现可能不同,因此对某些问题的理解也会不同,这里只是说明我自己的理解。
lab1 BUFFER POOL
1. LRU REPLACEMENT POLICY
-
Pages are stored on disk.
-
Memory region organized as an array of fixed-size pages. An array entry is called a frame.
-
When the DBMS requests a page, an exact copy is placed into one of these frames.
LRU算法本身并不难,但初看这个task可能还是有点懵,主要是没有上下文比较难理解Victim,Pin和Unpin到底是要做什么,做了task2后就很明白了。
2. BUFFER POOL MANAGER INSTANCE
首先要从大体上理解buffer_pool_manager(BPM)在做什么: 数据库数据以page为单位存在磁盘上,当要读取或修改page时,需要先将page加载到内存中。但一般内存是有限的,比磁盘小,不可能加载全部的page。BPM管理一块内存,可以看成是以page size为分段的数组,每一段称为一个frame。同时,BPM决定哪些page可以写入内存,哪些已经被写入page的内存要重新写回磁盘以让出内存空间。这些决定要用到LRU replacer作为决策的依据。
task2本身也不难,但需要非常清晰各个方法到底要做什么,不做什么,否则会很乱,下面是总结一些思考和过gradescope的提示:
-
NewPgImp()中新分配的页为什么不调用disk_manager_.ReadPage()? 因为NewPgImp的作用只是为数据库新申请一页的大小,有点像malloc()的感觉,可以写数据到NewPgImp()返回的页,但去读它是没有意义的,而且为了避免有内存脏数据,在NewPgImp()返回前还会特意将内存数据清零。只有FetchPgImp是真的尝试读取指定page的内容,会调用disk_manager_.ReadPage() -
UnpinPgImp()中page的pin为0后应该怎么处理? 只需要通知replacer去unpin对应的frame即可,不需要将frame加入free_list,不需要将page写回硬盘,也不用更新page_table去删除对应的page_id。pin_count为0只是说明当前page可以被替换回硬盘,但不代表要立马替换,因此可以保持其状态不变,只通知replacer。在必要时,replacer会victim对应的frame,这时才真正需要把page内容写回,更新page table,这样还可以提高性能,减少磁盘IO。
-
DeletePgImp()中删除一个page后,为什么和上一问不同,不仅要replacer调用unpin,还需要将frame加入free_list, 更新page_table? 这里delete不是指将page从buffer中删除,而是从整个数据库删除,这样page_id其实变成invalid了,需要从page_table中删除是显然的。但为什么还需要加入free_list,否则过不了gradescope。我理解这里和pin_count为0不同的是,这一帧的内存所有数据已经是invalid,本身就没有意义,从语义上说加入free_list更好(不加入的话功能也不会出错?) 那么反过来,既然已经将frame加入free_list了,为什么还要调用replacer.unpin,否则也过不了,这个问题还不是很懂!(TODO)
update: 当天晚上有点晕了,实际不replacer.unpin也是满分的,但一定要加入free_list,unpin确实没什么意义,能走到最后unpin那里的frame一定已经在replacer维护的队列中。那为什么要加入free_list而不是靠replacer轮换呢?首先比较明显的,加入free_list可以提升性能,但为什么不加入就会fail?可能还是有忽略的细节,暂时想不清楚
- unpin如果在page table中找不到对应的page,需要返回true
- unpin更新is_dirty时,应该
page->is_dirty_ |= is_dirty;,因为可能已经是脏页了,但执行unpin的线程没有对page修改,入参is_dirty是false - AllocatePage()和DeallocatePage()都只有在正常路径中被调用,比如AllocatePage应该在找到空余的frame后再调用。
3. PARALLEL BUFFER POOL MANAGER
因为task2中的方法都是加了锁的,所以task3简单的很多,但有一个4分的RoundRobinNewPage测试点老是不过,换了各种实现方法,加锁或不加锁都不过,也有可能不是NewPage本身的实现不对,没时间细看这个问题,留作TODO吧,也许做后面lab的时候对lab1有更深刻的理解。
lab2 EXTENDIBLE HASH INDEX
我感觉实验2比实验1好做,因为上下文比较清晰,知道每个方法作用是什么,在什么情况下被调用,只要按算法描述来实现就好了。而且也不用考虑极端情况,最后100/100通过gradescope,但性能垫底。
关于lab2的具体讲解可以看看这位大佬 或者这位大佬,这里不重复讲了。
几个可以考虑但gradescope不要求的点:
- 写锁细化到bucket级别,为了省事,Insert和Remove都是直接把整个哈希表用写锁保护起来,这也是性能垫底的原因。
- 一次插入可能需要多次分裂才能插入成功,甚至不能插入成功,因为一页内存只能保存有限个kv对,如果所有key都一样,那即使无限分裂也没用
- 一次合并可能会产生新的合并机会,也就是说可能合并后的bucket也是空的,且恰好有对应的”split image”,那就可以再来一次合并,但gradescope上对此不做要求
lab3 Query Execution
同样的,实现方法的具体讲解可以看上面两位大佬,这里只记录一点体会。整个lab3采用的是简单的volcano model或者叫pipeline model,整个算法思想并不难,但这一套executor、tuple、scheme等等的抽象我觉得非常nice。Bustub的绝大部分代码其实都已经是写好了的,lab只需要按部就班地填充一小部分实现就好,因此需要对每个接口到底在做什么,怎么用有清晰的了解。
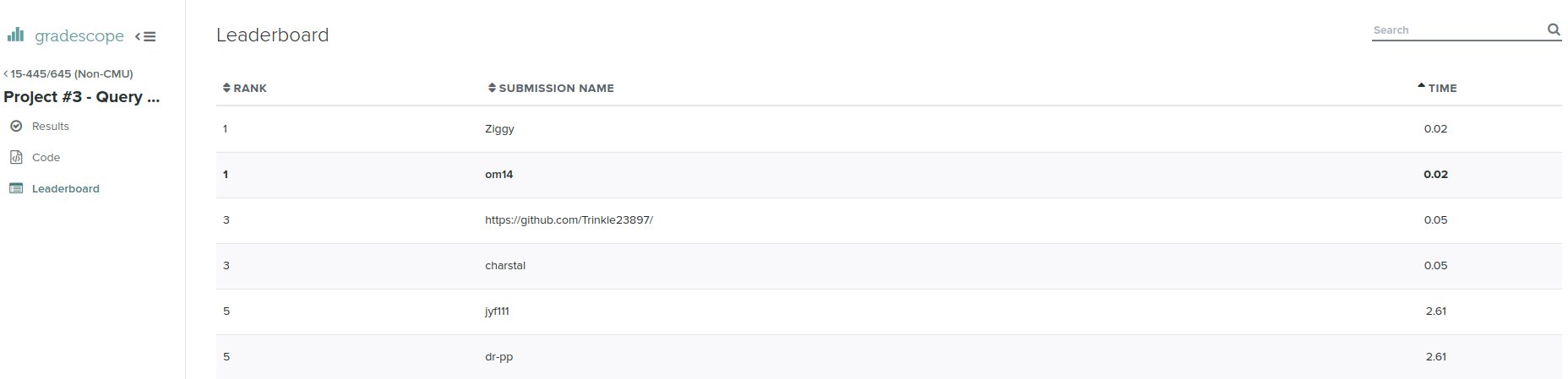
最后意外地在gradescope上跑分rank1,不是很清楚怎么回事,可能只是当时测评机状态比较好,不过也懒得重测了,毕竟rank1确实好看
lab4 Concurrency Control
具体讲解可以看这篇, 自己先独立做大概拿了60分,感觉又陷入lab1时不知道按什么规则维护相应数据结构的泥潭里,比如到底要往request_queue_里加哪些数据?什么时候将请求移出队列?什么时候notify?等问题。虽然最后100分通过,但这些问题可以有时间再重新思考下。最后一点体会: 关于数据库的锁,如果搜面经能搜出来的很多,但只有写过代码后才能体会很深。比如以前看事务的隔离级别,基本就靠死记硬背,现在能知道READ_UNCOMMITTED就是不加读锁只加写锁,因此可以读到其他事务中未提交的修改;READ_COMMITTED要加读锁但读完后就释放锁;REPEATABLE_READ要加读锁且只有事务提交后才释放锁。看上去高深的概念实际上实现起来只需要简单的修改,体现出算法的巧妙与简洁.