Kademlia: A Peer-to-Peer Information System Basedonthe XOR Metric
推荐读paper前先看这个,非常好地解释了XOR的来源
We describe a peer-to-peer distributed hash table with provable consistency and performance in a fault-prone environment.
1 Introduction
Kademlia是p2p分布式哈希表(DHT). Kademlia有一些之前其他DHT所不具有的特性。Kademlia减少了节点为了发现彼此而必须发送的配置信息,配置信息在查询key时自动作为side-effect发送。节点可以通过低延迟路径掌握足够的信息和灵活性(flexibility)去查询路由。Kademlia使用并行,异步查询避免宕机节点造成大的延迟。节点记录其他节点存在的算法可以抵御基础的denial of service attacks.
Kademlia的key是opaque 160-bit quantities(比如SHA-1 哈希值)。参与系统的每个计算机有一个160-bit的节点ID。<key, value>存储在节点里,这些节点的ID和key按某种概念来说是相近的。最终,一个 node-ID-based 路由算法能让任何人高效地定位到指定key的邻近服务器。
Kademlia的许多好处都来源于其对XOR的使用,用XOR度量key空间两个点的距离。
(注: 然后和其他DHT做了一些比较,不太看得懂,略过)
2 System Description
我们的系统采取和其他DHT一样的方法,为每个节点分配160-bit ID并且提供一种算法使要查找的id越来越近,差不多达到logN的复杂度。
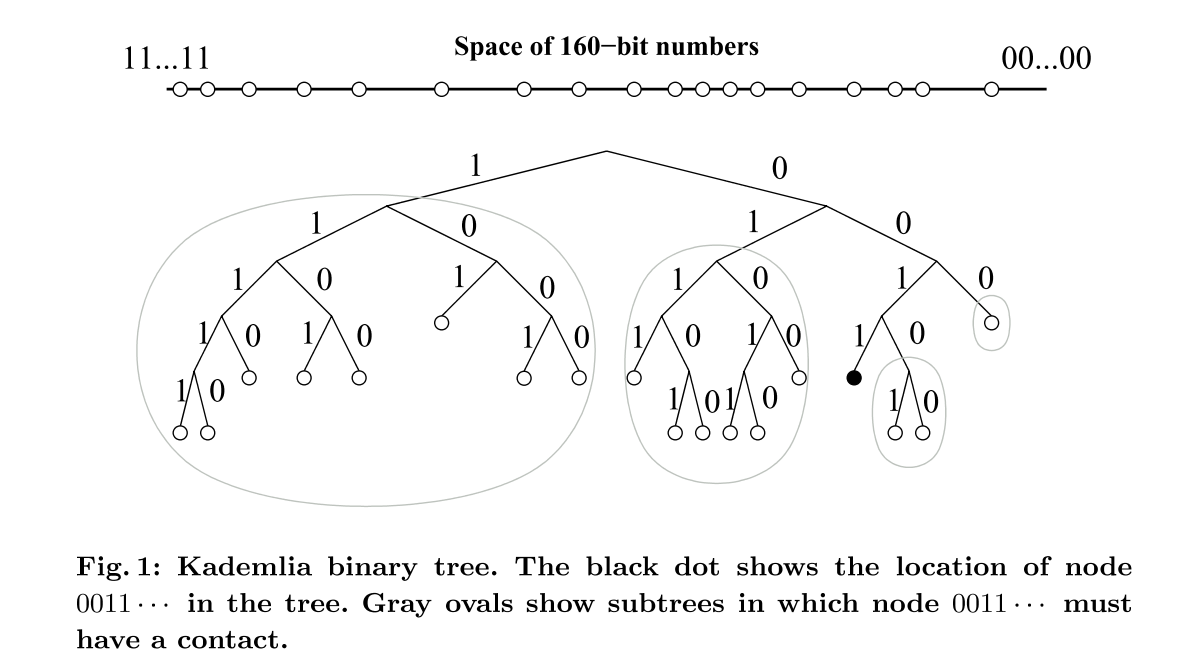
Kademlia将节点看作二叉树的叶子节点,每个节点的位置由ID的shortest unique prefix决定。然后将整颗二叉树分成若干个子树,这些子树都不包含给定的节点。比如图一中0011是给定节点,那么子树有1,01,000和0010。其实就是0011到根节点路径上所有中间节点的sibling组成的子树
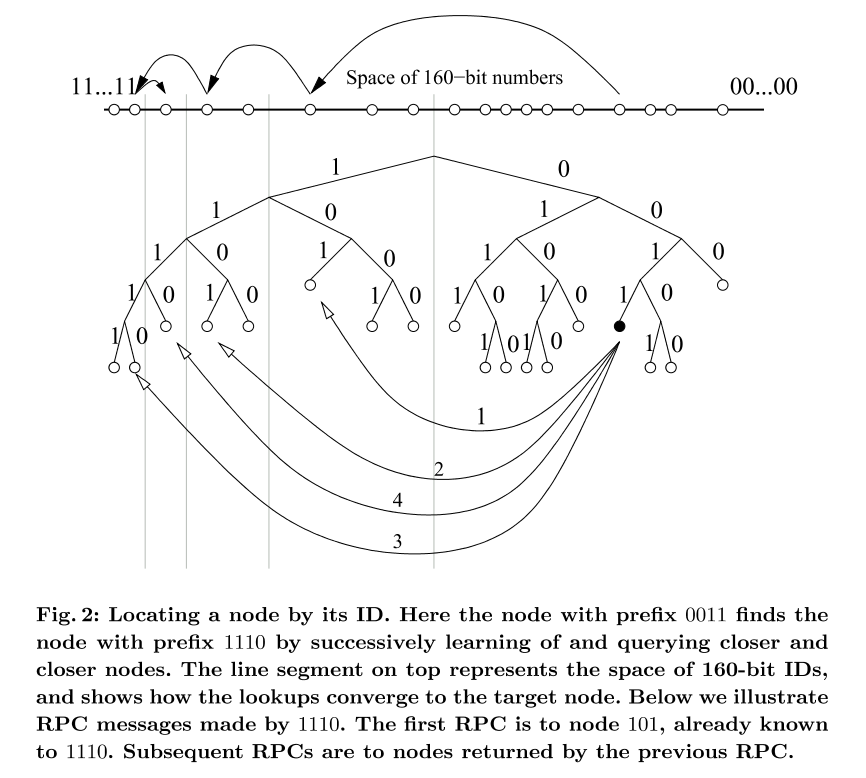
Kademlia协议还保证每个节点知道各种子树的至少的一个节点,有了这个保证后,任何节点可以通过ID定位其他节点。图二显示了查找的过程,具体过程解释在下文
2.1 XOR Metric
每个Kademlia节点有160-bit 节点ID。节点ID目前只是随机的160-bit标识。节点发送的每条消息都包含节点ID,可以让接收节点知道发送节点的存在。
<k, v>中的key也是160-bit标识符。为了给节点赋值<k, v>对,Kademlia依赖一种关于标识符距离的概念。给定两个160-bit标识符x和y,定义其距离就是x XOR y,也就是$d(x, y) = x \oplus y$。XOR作为距离的度量具有以下一些性质:
- $d(x, x) = 0$
- $d(x,y) = d(y,x)$
- $d(x,y) + d(y,z) \ge d(x,z)$
(注: XOR度量距离本质上就是找最长公共前缀)
2.2 Node State
Kademlia节点存储和其他节点的沟通信息以便于路由查询信息。对每个$0 \le i < 160$,每个节点维护一个<IP address, UDP port, Node ID>列表,列表中的节点距离自己$2^i$到$2^{i+1}$之间(注: 其实就是上文说的子树)。这些list被称为k-buckets。每个k-bucket按照节点最后被看见的时间排序,最近最少被看见的在列表头,最近被看到的在尾。对一些值较小的$i$,k-bucket往往是空的。对值较大的$i$,list可以增长到k值,k是system-wide replication parameter。k的选择是给定任意k个节点,几乎不可能在一小时内宕机,例如k = 20
当Kademlia节点收到新的消息(无所谓是请求或者回复)时,会更新发送方节点ID所在的k-bucket。如果节点ID已经在列表里了,就把ID移动到列表尾; 如果节点ID不在列表中且列表中ID不到k个,就把新的节点ID插入到列表尾; 如果列表已经满了,则尝试和列表头的最少访问节点通信,如果通信不成功就将其踢出列表,然后把新ID放在列表尾,如果通信成功,就把其从列表头移到尾,然后丢弃新收到的节点ID。
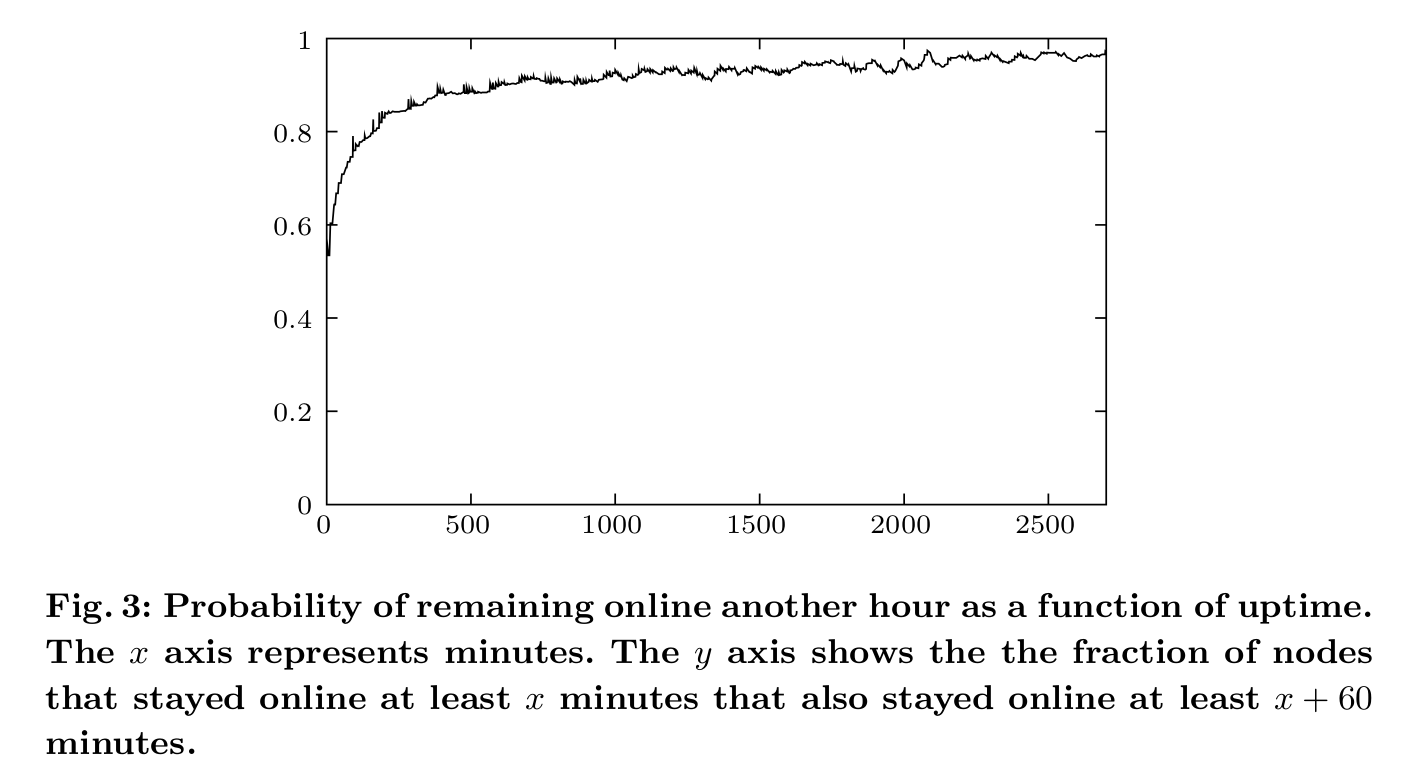
k-buckets高效地实现了类似LRU的更新策略,但有个特点是alive的节点永远不会被踢出队列,首先是因为在线时间越长的节点继续在线一小时的概率更大(如图三),所以选择保留旧节点可以提高节点在线的概率。其次,可以抵御一定程度的DoS攻击。攻击者不能通过增加新节点的方式来更新节点中的正常路由列表。
2.3 Kademlia Protocol
Kademlia协议包含4种RPC:
- PING 检测节点是否在线
- STORE 让一个节点存储<k, v>
- FIND_NODE 160-bit的Node ID作为参数,收到请求的节点需要返回<IP address, UDP port, Node ID>列表,列表中是该节点知道的离目标节点最近的k的节 点。一般地,应答节点必须保证回复列表中有k个节点,除非应答节点自己的k-buckets中所有已知节点都还不到k个
- FIND VALUE 和FIND_NODE差不多,返回<IP address, UDP port, Node ID>列表,但如果应答节点之前收到同一个key的STORE请求,就直接返回value
在所有的RPC中,接收者必须echo一个160-bit随机RPC ID,可以作为一点防伪手段。PING也可以作为RPC回复中捎带的请求,这样应答节点可以获取关于发送节点更准确的网络地址等信息。
Kademlia参与者必须执行的程序中,最重要的是定位离给定节点ID最近的k个节点,这个过程也叫node lookup。Kademlia采用一种递归算法。Lookup发起者首先从自己的k-buckets中选取$\alpha$个最近的节点。然后发起者向被选中的节点发送并行,异步的FIND_NODE RPC。$\alpha$是system-wide 并发系数,比如3.
在递归步骤中,发起者会从最开始的$\alpha$个节点中收到它们各自的k个最近节点,也就最多有$\alpha \times k $个新的节点信息,这些新节点信息会和发起者最初自己的k个节点再一起排序,然后访问还没有访问的前k个节点。重复这个步骤,直到前k个节点全部被访问过,距离最小的节点就是目标节点。
大多数操作都按上述lookup过程实现。要存储一个<K, V>时,参与者首先找到离key最近的k个节点,然后向它们发送STORE请求。此外,每个节点需要re-publishes <key, value>,<K, V>的到期时间可以由应用自身特点而定。
查找<k, v>时,节点首先查找离key最近的k个节点。但是,查询value还是用FIND_VALUE而不是FIND_NODE,因为找到value后可以理解结束查找。此外,为了缓存结果,当一次查找value成功后,<k, v>将保存在离key最近但没有返回value的节点中。
因为整个系统拓扑是无方向的,未来对同一个key的请求很可能hit cache而不需要查询最近的节点。但系统也可能将key缓存的太多。为了避免over-caching,we make the expiration time of a <key,value> pair in any node’s database exponentially inversely proportional to the number of nodes between the current node and the node whose ID is closest to the key ID。
buckets一般来说可以通过请求来更新,但有时候一个范围内的节点ID在过去一小时都没有任何查询,那么这时需要refresh操作,即随机选择一个该范围的ID,然后查询,相当于模拟真实请求。
新节点a加入网络时,必须已知一个已经存在的节点b。a把b插入合适的k-bucket中,a然后执行node lookup,查找节点是它自己。这样a可以更新自己的k-buckets,也可以让其他节点知道自己的存在。
2.4 Routing Table
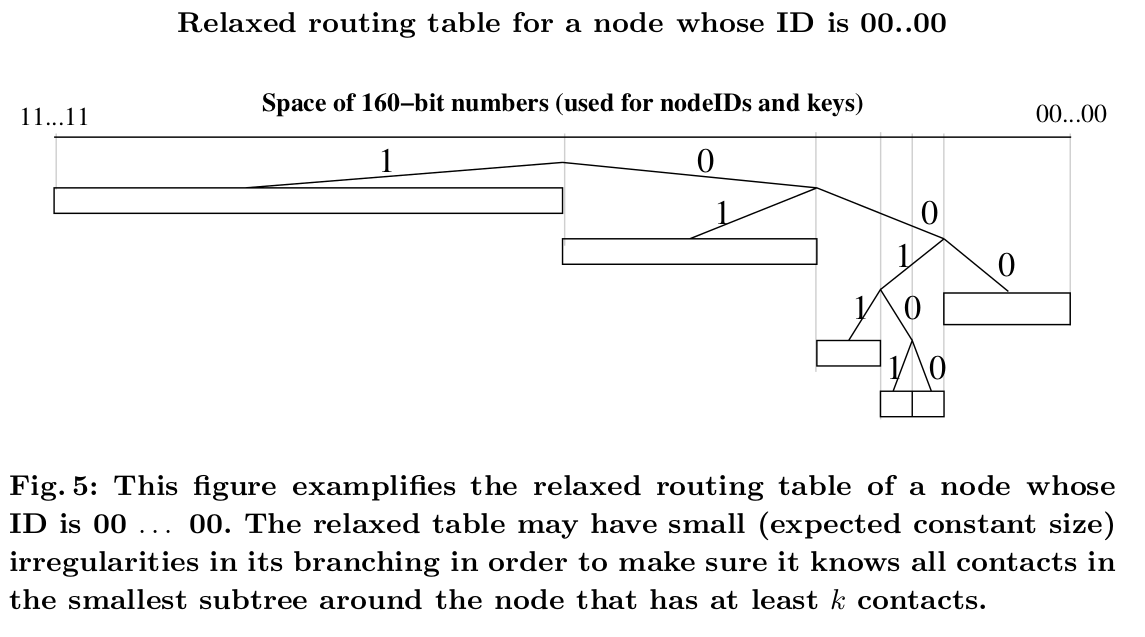
routing table本身的结构是很直白的,但有一些subtlety处理很不平衡的树。routing table是一颗二叉树,叶子节点是k-buckets。每个k-bucket包含的节点都有一些公共前缀。这个前缀就是k-bucket在二叉树中的位置。因此每个k-bucket包含一些范围内的ID,所有k-bucket组成160-bit空间且互相没有重叠。
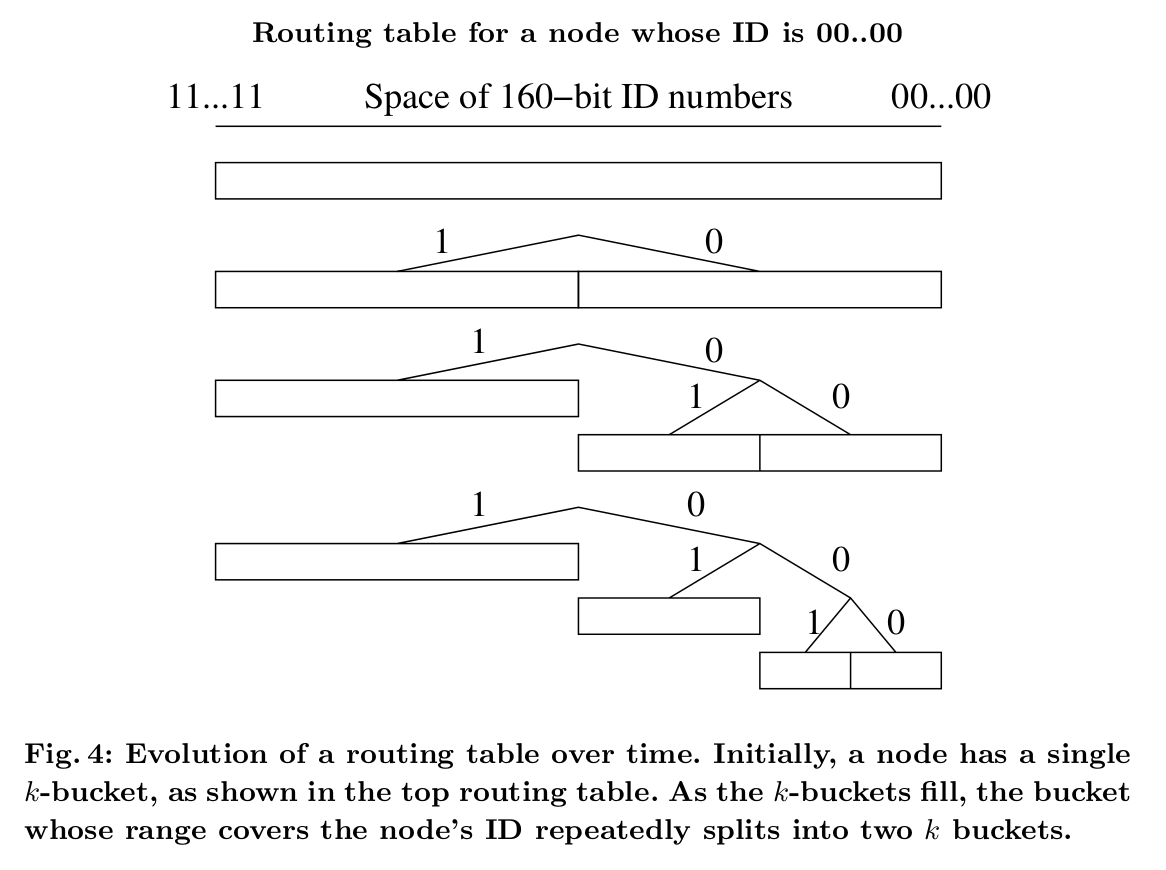
routing tree中的节点都是动态申请的。如图四,节点最开始只有1个节点,也就只有1个k-bucket,cover了整个id空间。当节点遇到新的节点后,尝试将新节点插入到合适的k-bucket中。如果bucket还没满,就插入到bucket中;如果满了,且bucket的范围包含节点自己,那么就将bucket分为两个buckets,再重新尝试插入;如果满的bucket不包含自己,那么就直接丢弃新的节点信息。